Python随笔
Python随笔
- Python随笔
前言
python 简介
- 创建 Python 的初衷是,通过屏蔽更多与硬件的复杂交互来简化软件开发。 缺点是 Python 对这些交互的控制力较弱。 因此,Python 可能不适合某些占用大量处理器时间的应用。
- 其他编程语言可以更好地控制与硬件的复杂交互。 如果使用得当,它们的性能比 Python 更好。 但它们可能更难以理解。 许多软件应用不需要通过这种程度的优化来提高性能。
什么是编译
- 什么是编译? - Learn | Microsoft Docs
- 编写完源代码后,通常会使用一个称为 编译器 的特殊程序。 该程序可将源代码转换为计算机 CPU 可以运行的格式。
Python 的工作原理
Python 具有编译器。 但是,该编译器不会将源代码直接转换为计算机可以理解的格式, 而是以特殊格式生成 Python 解释器可以解释和运行的代码。
解释器 是运行每个指令的程序。 它跟踪 RAM 中值的存储位置。 解释器还知道如何与文件系统或网络等外部资源进行交互。
换句话说,解释器是一个执行环境,它管理你的意图与计算机内部运作之间的复杂交互。
Python 解释器可用于许多计算机平台。 例如,如果在 Linux 上编写了 Python 代码,该代码也将在 macOS 和 Windows 上运行。 无需为特定计算平台编译源代码就可以运行程序。
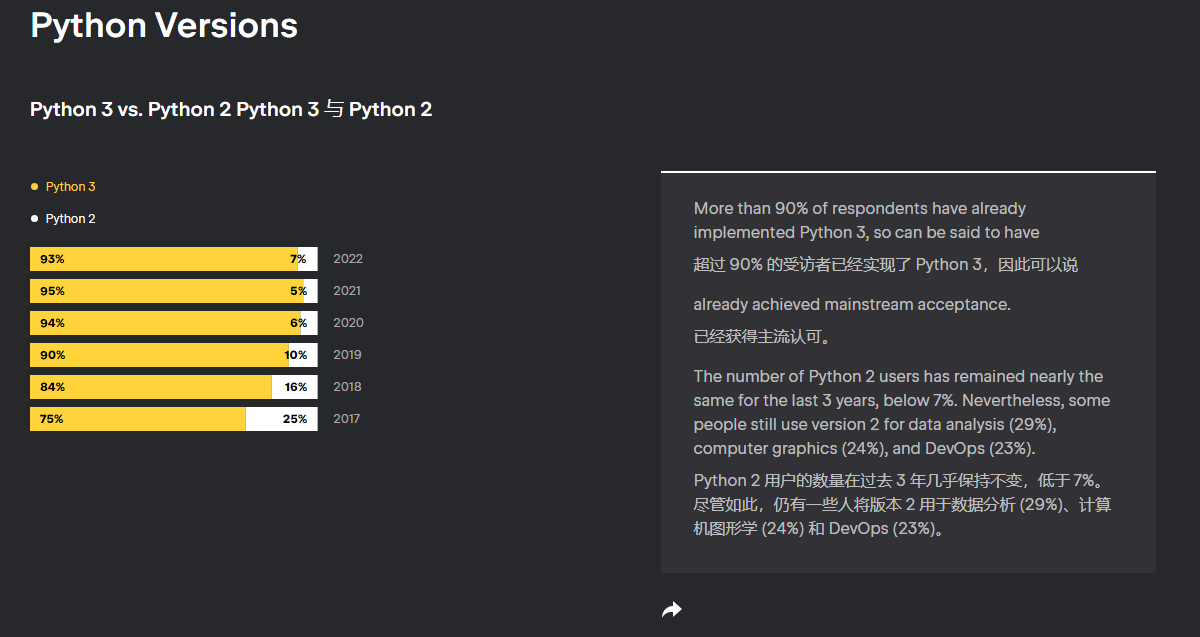
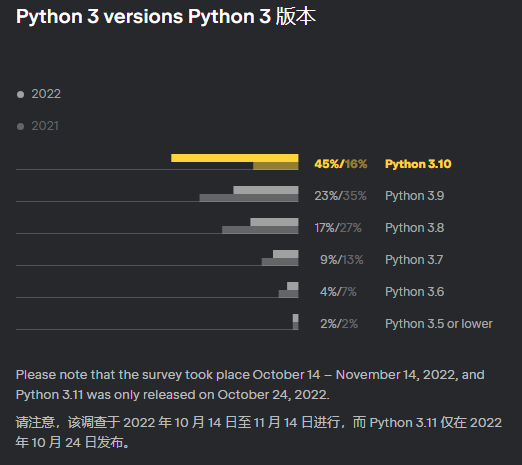
当前 python 各版本的使用情况
换源操作
py -3.8 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencc
py -3.8 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
py -3.8 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
- 镜像源地址
- 阿里云
https://mirrors.aliyun.com/pypi/simple/ - 中国科技大学
https://pypi.mirrors.ustc.edu.cn/simple/ - 豆瓣(douban)
http://pypi.douban.com/simple/ - 清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/ - 中国科学技术大学
http://pypi.mirrors.ustc.edu.cn/simple/
- 阿里云
- 补充:将包装到指定路径:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pygame --target=C:/Users/233/AppData/Local/Programs/Python/Python38/Lib/site-packages
code2flow ---- 根据 python 代码生成项目结构及函数调用图
概述(摘自项目README)
Code2flow generates call graphs for dynamic programming language. Currently, code2flow supports Python and Javascript.
The basic algorithm is simple:
- Find function definitions in your project's source code.
- Determine where those functions are called.
- Connect the dots.
Code2flow is useful for:
- Untangling spaghetti code.
- Identifying orphaned functions.
- Getting new developers up to speed.
安装
clonecode2flow 仓库 或者download Zip或者在此处获取我下好的仓库压缩包 (2021.5.22) 并解压- 在此处选择系统相应版本的软件进行下载;或者在此处获取我下好的版本 (
Windows 10 (64-bit) v-2.47.1); 下载完后运行并安装此软件(安装过程中记得勾选添加环境变量) - 选择一个自己趁手的
python 环境管理工具(这里我用的anaconda) 在一个python 环境下打开命令行(我直接用的 Pycharm 打开项目 然后选择一个 conda 环境作为项目的python解释器之后在Pycharm的终端命令行中执行的)- 在项目根目录执行
python setup.py install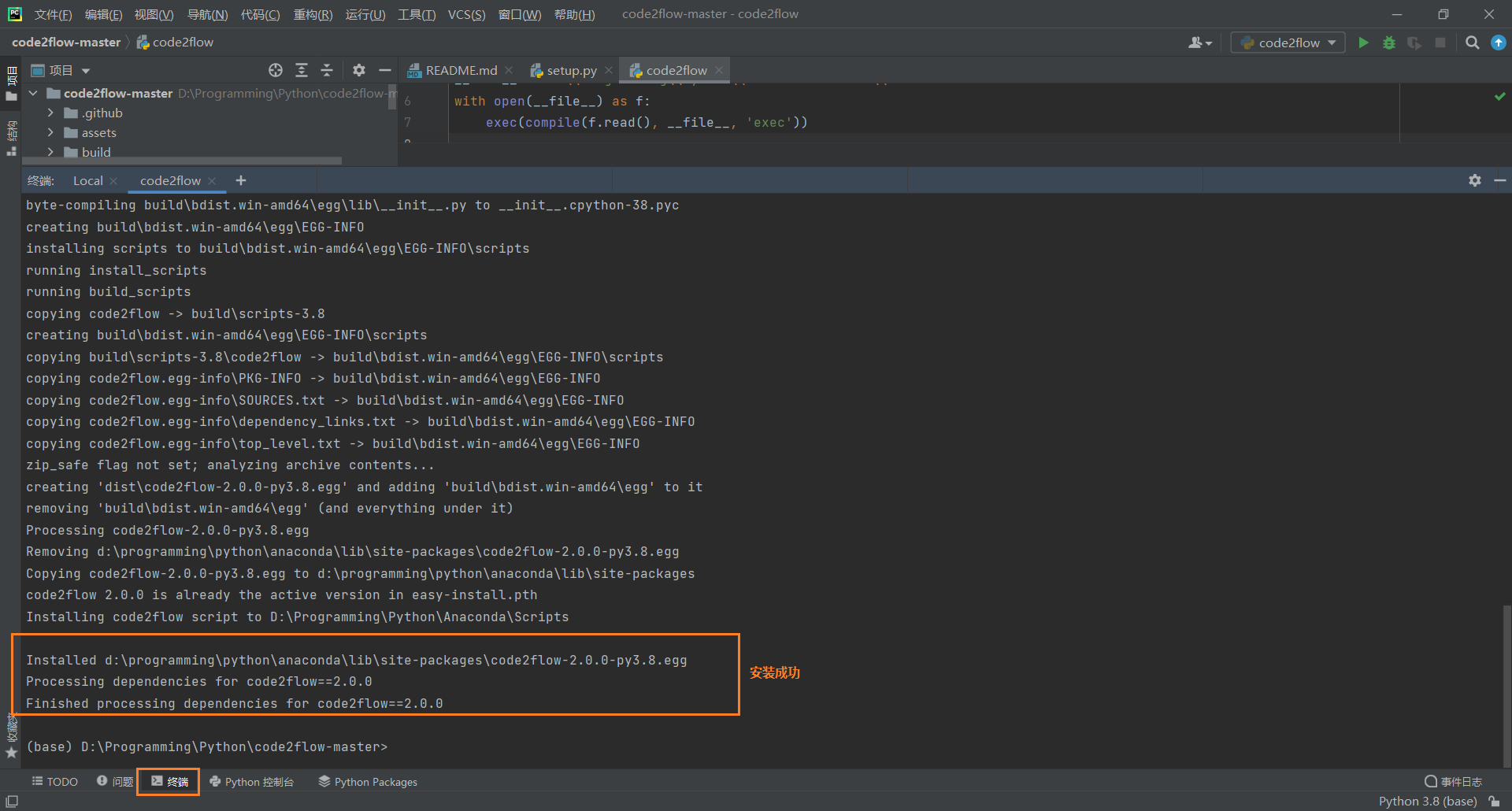
- 成功安装后在当前 python 环境的根目录下的
Scripts目录下可以看到一个code2flow文件
- 在项目根目录执行
使用
不支持中文,注释也不行,因此第一步就是要给待会要作为基底生成流程图的python文件去中文注释
由于
VSCode的查询功能有正则匹配的模式,所以想到使用VSCode直接去除整个文档的注释- 记得备份原文档(直接使用拷贝文档就是了)
- (
^#.*匹配以#开头后接任意个任意字符的语句来去掉注释行)[PS :.不会匹配\n(换行)] 匹配行首注释 #.*匹配行尾注释
将去除注释的文件和 安装过程中最后指出的
Scripts目录下的code2flow文件拷贝到同一文件目录下并用已经安装好code2flow的python环境打开该文件夹并打开命令行执行python code2flow mypythonfile.py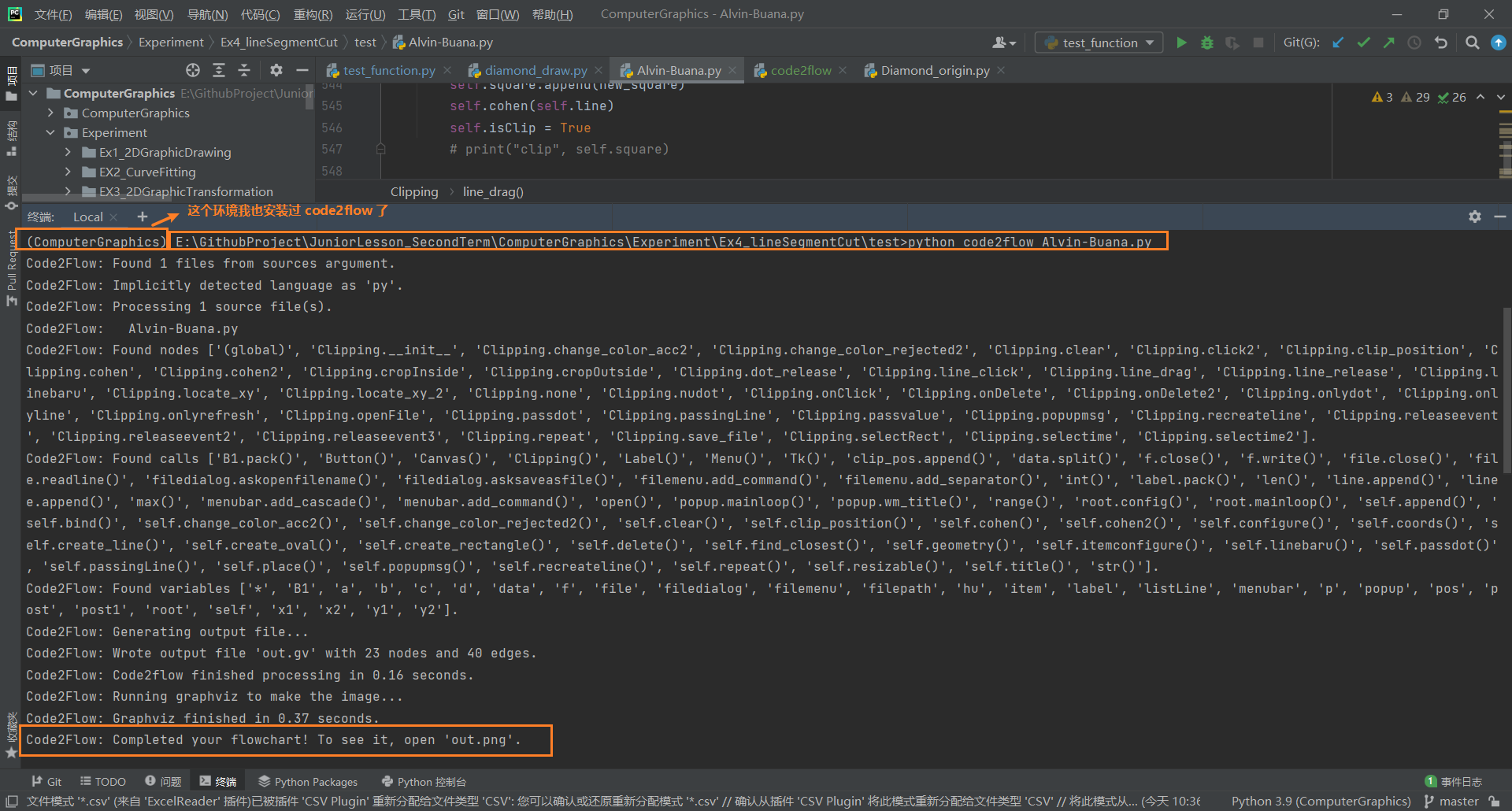
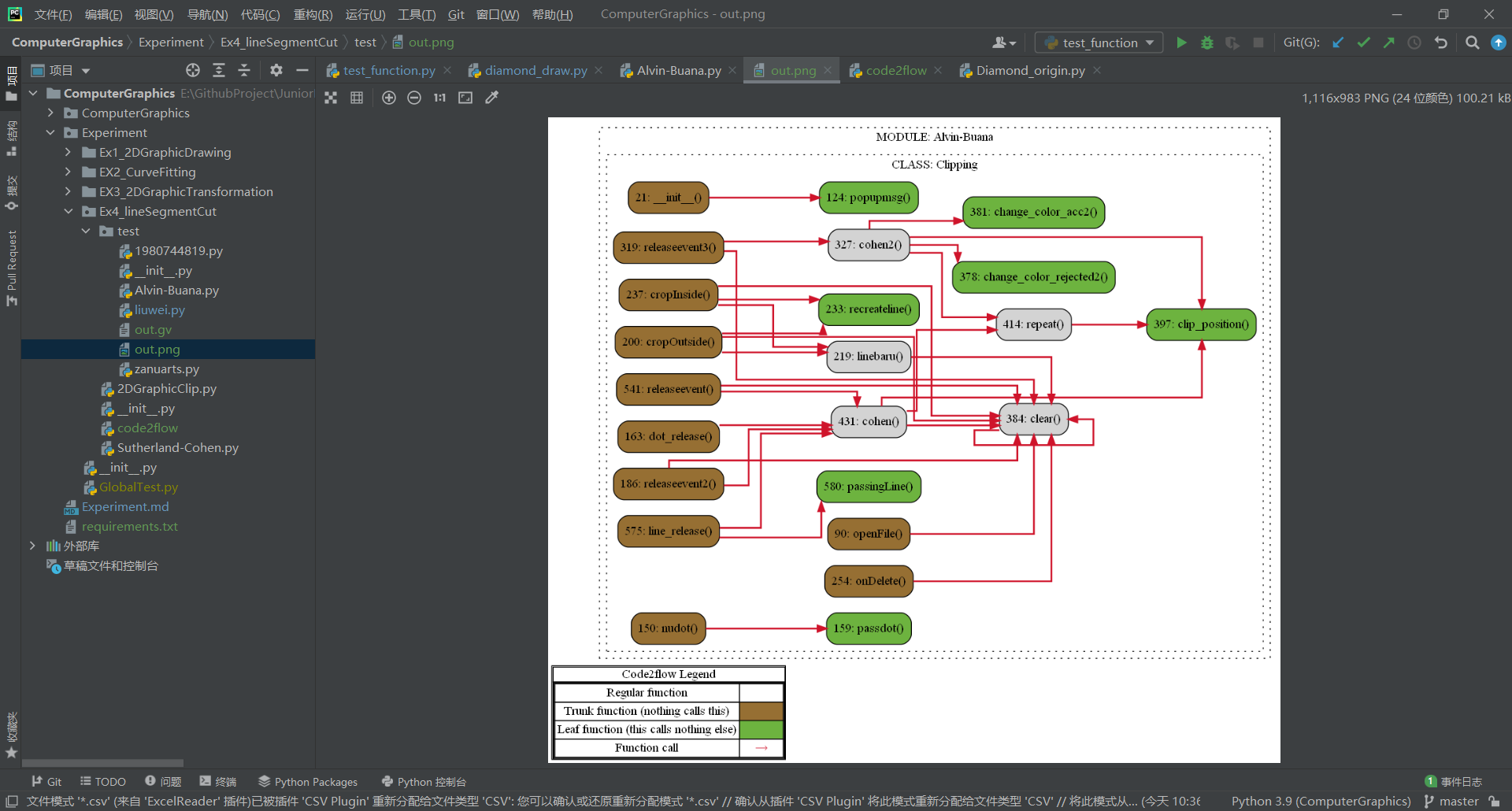
程序性能分析
执行时间
pyinstrument
pip install pyinstrument
用例: 单文件脚本分析并输出 html 分析页
pyinstrument -r html script.py
使用datetime判断
import datetime
# 程序开始处:
begin = datetime.datetime.now()
# 程序结束处:
end = datetime.datetime.now()
print("程序执行时间:{0}".format(end-begin))
内存占用
guppy3
- 安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple guppy3 - 使用
from guppy import hpy
h = hpy()
print(h.heap())
使用memory_profiler查看
- 安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U memory_profiler - 使用
import memory_profiler @memory_profiler.profile def 函数名(): 你要测试内存占用的代码 函数名() # 运行此函数
import 相关
相对导入引发的相关问题
python - ImportError : Attempted relative import with no known parent package - Stack Overflow
python - Relative imports for the billionth time - Stack Overflow
ModuleNotFoundError
ModuleNotFoundError: No module named '__main__.src_test1'; '__main__' is not a package
一般出现于运行的当前文件中通过相对引用 .xxx 引入其他模块时由于运行时当前模块名为 __main__ 所以会对相对引用路径进行拼接导致引用错误
解决方法: 引用当前文件同级目录下的模块可以不用 . 拼接直接 import xxx
ImportError
ImportError: attempted relative import with no known parent package
|--- test_main.py
|--- src
|--- __init__.py
|--- src_test1.py
|--- src_test2.pys
|--- test_src.py
src_test1.py:
from .src_test2 import Test2
def func1():
pass
test_src.py:
from src_test1 import fun1
运行 test_src.py 会上述错误, 问题在于引入 src_test1 时, src_test1 内使用 . 拼接相对路径引用 src_test2, 由于 . 的存在, 需要先找到父包才能继续拼接路径, 但是当前 test_src.py 被认为是根结点(没有父包), 所以会报 no know parent package
解决方案
需要注意的是: 上面的报错都是运行时报错, 在编写代码时至少 VSCode 是不会报错的, 那么个人的解决方案就是将主业务全放在工作区根目录下的一个目录下, 然后在根目录放一个 py 文件调用程序主入口来启动程序
基础杂项
函数注释
Rest 风格的注释:
"""
This is a reST style.
:param param1: this is a first param
:param param2: this is a second param
:returns: this is a description of what is returned
:raises keyError: raises an exception
"""
深浅拷贝
- 该部分来源
- 直接赋值:其实就是对象的引用(别名) 。
- 浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
字典浅拷贝实例
>>>a = {1: [1,2,3]}
>>> b = a.copy()
>>> a, b
({1: [1, 2, 3]}, {1: [1, 2, 3]})
>>> a[1].append(4)
>>> a, b
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})
深度拷贝需要引入 copy 模块:
>>>import copy
>>> c = copy.deepcopy(a)
>>> a, c
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})
>>> a[1].append(5)
>>> a, c
({1: [1, 2, 3, 4, 5]}, {1: [1, 2, 3, 4]})
解析
b = a: 赋值引用,a 和 b 都指向同一个对象。
b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用) 。
b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
逻辑符号
- and的优先级要大于or
- a and b语句的输出全看a的Boolean值,如果a为True,输出b;反之,如果a为False,输出a
- a or b语句的输出也全看a的Boolean值,如果a为True,输出a;反之,如果a为False,输出b
- 在python中not是逻辑判断词,用于布尔型True和False,notTrue为False,notFalse为True
- 只有0、None、空、False的布尔值为False,其余的为True。
- 参与数学运算时,True->1,False->0;
随手记
- id是内置函数,不能作为变量名使用
输出
- print函数的参数end表示分隔参数(默认为回车)
Python格式化输出 %s %d %f
- %% 百分号标记
- 就是输出一个%
- %c 字符及其ASCII码
- %s 字符串
- %d 有符号整数(十进制)
- %u 无符号整数(十进制)
- %o 无符号整数(八进制)
- %x 无符号整数(十六进制)
- %X 无符号整数(十六进制大写字符)
- %e 浮点数字(科学计数法)
- %E 浮点数字(科学计数法,用E代替e)
- %f 浮点数字(用小数点符号)
- %g 浮点数字(根据值的大小采用%e或%f)
- %G 浮点数字(类似于%g)
- %p 指针(用十六进制打印值的内存地址)
- %n 存储输出字符的数量放进参数列表的下一个变量中
% 格式化符也可用于字典,可用 %(name) 引用字典中的元素进行格式化输出。
负号指时数字应该是左对齐的,“0”告诉Python用前导0填充数字,正号指时数字总是显示它的正负(+,-)符号,即使数字是正数也不例外。
可指定最小的字段宽度,如:"%5d" % 2。
也可用句点符指定附加的精度,如:"%.3d" % 3。
# 例:数字格式化
nYear = 2018
nMonth = 9
nDay = 12
# 格式化日期 %02d数字转成两位整型缺位填0
print ('%04d-%02d-%02d' %(nYear,nMonth,nDay))
>> 2018-09-12 # 输出结果
fValue = 8.123
print ('%06.2f' %fValue) # 保留宽度为6的2位小数浮点型
>> 008.12 # 输出
print ('%d' %10) # 输出十进制
>> 10
print ('%o' %10) # 输出八进制
>> 12
print ('%02x' %10) # 输出两位十六进制,字母小写空缺补零
>> 0a
print ('%04X' %10) # 输出四位十六进制,字母大写空缺补零
>> 000A
print ('%.2e' %1.2888) # 以科学计数法输出浮点型保留2位小数
>> 1.29e+00
格式化操作符辅助指令: 符号 作用:
*: 定义宽度或者小数点精度-: 用做左对齐+: 在正数前面显示加号( + )<sp>: 在正数前面显示空格#: 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于 用的是'x'还是'X')0: 显示的数字前面填充‘0’而不是默认的空格%:%%输出一个单一的%(var): 映射变量(字典参数)m.n: m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话)
带颜色的输出
ANSI 转义序列是一系列字符,用于控制文本格式,如颜色、加粗等。
可以在Python中使用ANSI转义序列来打印彩色文本, 例如:
# ANSI转义序列示例
RED = "\033[31m" # 红色文本
GREEN = "\033[32m" # 绿色文本
YELLOW = "\033[33m" # 黄色文本
BLUE = "\033[34m" # 蓝色文本
PINK = "\033[35m" # 粉红色文本
RESET = "\033[0m" # 重置颜色
# 导入 windows-index yaml 文档
print(YELLOW + "正在导入 windows-index.yaml 文档, 文档比较大,可能需要一些时间......" + RESET)
print(GREEN + "windows-index.yaml 文档导入完成" + RESET)
不过像这样的 print 语句并不好全局控制, 因此要输出彩色信息的话其实可以使用 logging 模块, 也方便全局控制日志等级, 例如:
random
randint用于生成正数类型随机数
- n = randint(20, 100) # 20<=n<=100
时间
time.localtime()
- 描述:
- Python time localtime() 函数类似gmtime(),作用是格式化时间戳为本地的时间。 如果sec参数未输入,则以当前时间为转换标准。
- DST (Daylight Savings Time) flag (-1, 0 or 1) 是否是夏令时。
- 语法:
- time.localtime([ sec ])
- 参数:
- sec -- 转换为time.struct_time类型的对象的秒数。
- 返回值:
- 该函数没有任何返回值。
运算符
海象运算符
Python 海象运算符 := 是在 PEP 572 中提出,并在 Python3.8 版本并入发布。
海象运算符 := 可用于在表达式中赋值,例如:
a = 2
if a > 1:
print("233")
用 := 写的话就是:
if a:=2 > 1:
print("233")
函数
返回函数参数表及参数数目
lamda函数:定义匿名函数
g = lambda x:x+1
相当于:
def g(x):
return x+1
函数注释
- 例子:
def dog(name:str, age:(1, 99), species:'狗狗的品种') -> tuple:
return (name, age, species)
- 查看这些注释可以通过自定义函数的特殊属性__annotations__获取,结果会议字典的形式返回:
dog.__annotations__
# {'age': (1, 99), 'name': str, 'return': tuple, 'species': '狗狗的品种'}
- 另外,使用函数注释并不影响默认参数的使用:
def dog(name:str ='dobi', age:(1, 99) =3, species:'狗狗的品种' ='Labrador') -> tuple:
return (name, age, species)
*args,**kwargs
*args的用法
- 当传入的参数个数未知,且不需要知道参数名称时使用*args;
**kwargs的用法
- 当传入的参数个数未知,但需要知道参数的名称时(立马想到了字典,即键值对)
def func_kwargs(farg, **kwargs):
print("formal arg:", farg)
for key in kwargs:
print("keyword arg: %s: %s" % (key, kwargs[key]))
func_kwargs(1 ,id=1, name='youzan', city='hangzhou',age ='20',四块五的妞是 = '来日方长的')
print('--------------------')
# 输出结果如下:
# formal arg: 1
# keyword arg: id: 1
# keyword arg: name: youzan
# keyword arg: city: hangzhou
# keyword arg: age: 20
# keyword arg: 四块五的妞是: 来日方长的
#利用它转换参数为字典
def kw_dict(**kwargs):
return kwargs
print(kw_dict(a=1,b=2,c=3))
# 输出结果如下:
# --------------------
# {'a': 1, 'b': 2, 'c': 3}
函数装饰器
Python 一切皆对象, 函数也不例外, 可以通过将函数赋给变量, 这样通过该变量也可以调用该函数
def Func1():
print("Hello")
f = Func1
f()
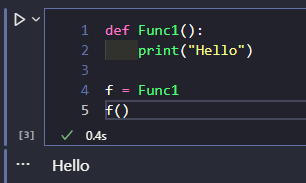
可以通过函数的 __name__ 属性拿到函数名:
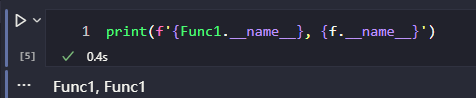
如果现在有个需求是在每个函数执行时都要输出日志, 那么此时可以使用 decorator(装饰器), 比如如下装饰器:
# %%
# 输出日志的函数装饰器
def log(func):
def wrapper(*args, **kwargs):
print(f'call {func.__name__}()')
return func(*asrgs, **kwargs)
return wrapper
要使用这个装饰器需要用 @ 语法将其置于被装饰函数的定义处, 如:
@log
def func2():
print("亻尔女子")
func2()
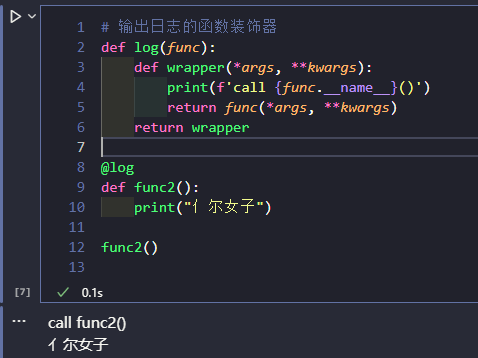
将 @log 放在 func2 的定义处, 相当于执行了:
func2 = log(func2)
由于 log 是个装饰器, 返回一个函数, 所以原来的 func2 依然存在, 只是同名的 func2 变量指向了新的函数, 于是使用 func2() 将会执行新的函数, 也即 log() 中返回的 wrapper()
wrapper() 的参数为 (*args, **kwagrs) 可以接收任一参数, 在 wrapper() 中先打印了日志接着调用了原本的函数
带参数的三层装饰器
如果装饰器本身需要传入参数的话则需要再多编一层函数, 比如给 log 加上自定义文本前缀
# 给 log 加上自定义文本前缀
def log(text):
def decorator(func):
def wrapper(*args, **kwargs):
print(f'{text}, {func.__name__}()')
return func(*args, **kwargs)
return wrapper
return decorator
用 log 装饰函数用法如下:
@log('execute')
def func3():
print('你好')
func3()
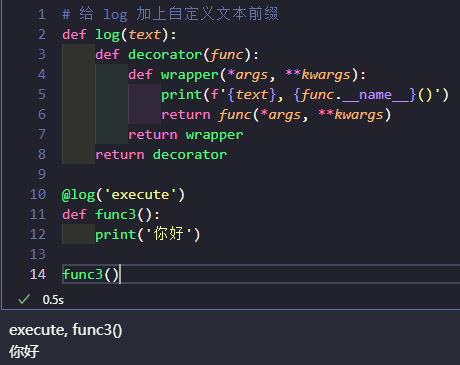
对齐被装饰函数属性
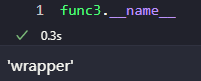
由于函数也是对象, 有 __name__ 等属性, 使用上述写法的装饰器再调用装饰完的函数的 __name__ 会发现已经变成 wrapper 了
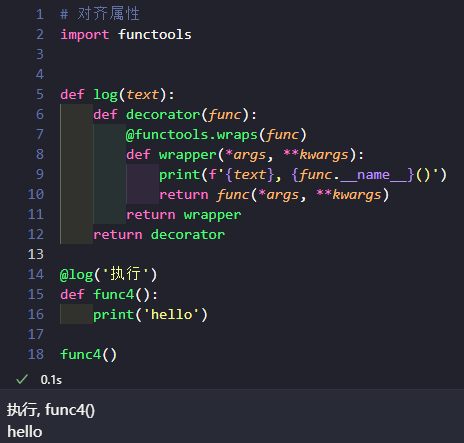
而有些依赖函数签名的代码使用这种装饰器的话就会报错, 此时需要将被装饰函数的属性也移过来, 不过倒不需要手动 wrapper.__**__ = func.__**__, python 有个内置的 functools.wraps 可以实现此操作:
# 对齐属性
import functools
def log(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f'{text}, {func.__name__}()')
return func(*args, **kwargs)
return wrapper
return decorator
@log('执行')
def func4():
print('hello')
func4()
可迭代序列
切片操作
- 逆序
print(txt[::-1])
ASCII码
chr()函数
- 描述
chr() 用一个范围在 range(256) 内的(就是0~255) 整数作参数,返回一个对应的字符。 - 用法
chr(i)- i -- 可以是10进制也可以是16进制的形式的数字。
- 返回值是当前整数对应的 ASCII 字符。
List
列表
index()
index() 函数用于从列表中找出某个值第一个匹配项的索引位置。
用法
list.index(x[, start[, end]])
- x-- 查找的对象。
- start-- 可选,查找的起始位置。
- end-- 可选,查找的结束位置。
- 该方法返回查找对象的索引位置,如果没有找到对象则抛出异常。
删除列表中某个元素的3种方法
- 参考
- remove、pop、del:
1.remove
- 删除单个元素,删除首个符合条件的元素,按值删除
# 举例说明:
>>> str=[1,2,3,4,5,2,6]
>>> str.remove(2)
>>> str
>>> [1, 3, 4, 5, 2, 6]
2.pop
- 删除单个或多个元素,按位删除(根据索引删除)
>>> str=[0,1,2,3,4,5,6]
>>> str.pop(1) #pop删除时会返回被删除的元素
>>> str
>>> [0, 2, 3, 4, 5, 6]
>>> str2=['abc','bcd','dce']
>>> str2.pop(2)
>>> 'dce'
>>> str2
>>> ['abc', 'bcd']
3.del
- 它是根据索引(元素所在位置)来删除
# 举例说明:
>>> str=[1,2,3,4,5,2,6]
>>> del str[1]
>>> str
>>> [1, 3, 4, 5, 2, 6]
>>> str2=['abc','bcd','dce']
>>> del str2[1]
>>> str2
>>> ['abc', 'dce']
- 除此之外,del还可以删除指定范围内的值。
>>> str=[0,1,2,3,4,5,6]
>>> del str[2:4] #删除从第2个元素开始,到第4个为止的元素(但是不包括尾部元素)
>>> str
>>> [0, 1, 4, 5, 6]
- del 也可以删除整个数据对象(列表、集合等)
>>> str=[0,1,2,3,4,5,6] >>> del str >>> str #删除后,找不到对象Traceback (most recent call last): File "<pyshell#27>", line 1, in <module> str NameError: name 'str' is not defined
注意:del是删除引用(变量)而不是删除对象(数据),对象由自动垃圾回收机制(GC) 删除。
补充: 删除元素的变相方法
s1 = (1, 2, 3, 4, 5, 6)
s2 = (2, 3, 5)
s3 = []
for i in s1:
if i not in s2:
s3.append(i)
print('s1_1:', s1)
s1 = s3
print('s2:', s2)
print('s3:', s3)
print('s1_2:', s1)
sort()
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
用法
list.sort( key=None, reverse=False)
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认) 。
- 注意:该方法没有返回值,但是会对列表的对象进行排序。
- list.sort()改变自身
- sorted(list)生成新列表
map()
map() 会根据提供的函数对指定序列做映射。
用法
map(function, iterable, ...)
- function -- 函数
- iterable -- 一个或多个序列
- 第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
- 返回值
- Python 2.x 返回列表。
- Python 3.x 返回迭代器。
示例:
>>>def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
# 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
注意点:map对象只能访问一次
A_object = map(str,range(3))
A_list = list(A_object)
B_list = list(A_object)
# 观察A_list,其值为 ['1','2','3']
# 观察B_list,其值为 []
- 这是由于,map函数返回的,是一个“可迭代对象”。
- 这种对象,被访问的同时,也在修改自己的值。
- 类似于 a = a+1
- 这样。对于map来说,就是每次访问,都把自己变为List中的下一个元素。
- 循环取得对象中的值 ,实际上是会调用内部函数__next__,将值改变,或者指向下一个元素。
- 当多次调用,代码认为到达终点了,返回结束,或者__next__指向空,此时可迭代对象(链表) 就算到终点了,不能再用了。
- 这种对象,被访问的同时,也在修改自己的值。
实验:
>>A_object = map(str,range(3))
>>num = A_object.__next__()
>>num
'0'
>>num = A_object.__next__()
>>num
'1'
>>A_list = List(A_object)
>>A_list
['2']
#此时,A_object已经指向最末尾,空元素了。再次调用next试试
>>num = A_object.__next__()
Traceback( most recent call last):
Filr "<stdin>" ,line 1 , in <module>
StopIteration
可见,该对象已经到了终点了,不能用了。
- 类似于 list(A_object) 或者 for num in A_object 这样的语句,就是调用了迭代器,执行了__next__,消耗了迭代对象。所以,再次使用A_object后,会发现它已经空了。
示例
list_x = [3, 8, 2, 6, 8]
print("list_x = [3, 8, 2, 6, 8]")
list_w = [2000, 3000, 2500, 1000, 1500]
print("list_w = [2000, 3000, 2500, 1000, 1500]")
list_c = [0.050, 0.050, 0.075, 0.075, 0.075]
print("list_c = [0.050, 0.050, 0.075, 0.075, 0.075]")
wc = map(lambda w, c: w * c, list_c, list_w)
print("wc = map(lambda w, c: w * c, list_c, list_w) = {0}".format(wc))
print("list(wc):{0}".format(list(wc)))
wcx = map(lambda w, c, x: w * c * x, list_c, list_w, list_x)
print("wcx = map(lambda w, c, x: w * c * x, list_c, list_w, list_x) = {0}".format(wcx))
print("list(wcx):{0}".format(list(wcx)))
a = sum(wcx)
print("a = sum(wcx) = {0} ; wcx = {1}".format(a, wcx))
b = sum(wc)
print("b = sum(wc) = {0}".format(b))
print("wc = {0}".format(wc))
print("type(a) = {0}, type(b) = {1}".format(type(a), type(b)))
x1 = a / b
print("x1 = a / b = {0}".format(x1))
print("sum(wc):{0} \n type(sum(wcx)):{1} \n type(sum(wc)):{2} \n".format(sum(wc), type(sum(wcx)), type(sum(wc))))
print("wc:{0}".format(wc))
print("wcx:{0}".format(wcx))
x1 = sum(wcx) / sum(wc)
print("x1 = sum(wcx) / sum(wc) = {0}".format(x1))
# 运行结果:
list_x = [3, 8, 2, 6, 8]
list_w = [2000, 3000, 2500, 1000, 1500]
list_c = [0.050, 0.050, 0.075, 0.075, 0.075]
wc = map(lambda w, c: w * c, list_c, list_w) = <map object at 0x00000210CFA9A070>
list(wc):[100.0, 150.0, 187.5, 75.0, 112.5]
wcx = map(lambda w, c, x: w * c * x, list_c, list_w, list_x) = <map object at 0x00000210CFA9A040>
list(wcx):[300.0, 1200.0, 375.0, 450.0, 900.0]
a = sum(wcx) = 0 ; wcx = <map object at 0x00000210CFA9A040>
b = sum(wc) = 0
wc = <map object at 0x00000210CFA9A070>
type(a) = <class 'int'>, type(b) = <class 'int'>
Traceback (most recent call last):
File "E:/GithubProject/MyProJect/JuniorLessons_beta/BigDataMicroMajor/Python/globalTest.py", line 19, in <module>
x1 = a / b
ZeroDivisionError: division by zero
问题示例
list_x = [3, 8, 2, 6, 8]
list_w = [2000, 3000, 2500, 1000, 1500]
list_c = [0.050, 0.050, 0.075, 0.075, 0.075]
wc = map(lambda w, c: w * c, list_c, list_w)
wcx = map(lambda w, c, x: w * c * x, list_c, list_w, list_x)
a = sum(wcx)
b = sum(wc)
print(type(a), type(b))
x1 = a / b
print(x1)
print(sum(wc), type(sum(wcx)), type(sum(wc)))
x1 = sum(wcx) / sum(wc)
print(x1)
# 运行结果:
Traceback (most recent call last):
File "E:/GithubProject/MyProJect/JuniorLessons_beta/BigDataMicroMajor/Python/globalTest.py", line 12, in <module>
x1 = sum(wcx) / sum(wc)
ZeroDivisionError: division by zero
<class 'float'> <class 'float'>
5.16
0 <class 'int'> <class 'int'>
# 原因解释:
list_x = [3, 8, 2, 6, 8]
list_w = [2000, 3000, 2500, 1000, 1500]
list_c = [0.050, 0.050, 0.075, 0.075, 0.075]
wc = map(lambda w, c: w * c, list_c, list_w)
wcx = map(lambda w, c, x: w * c * x, list_c, list_w, list_x)
a = sum(wcx)
print("list(wcx) = {0}".format(list(wcx)))
print("wcx._next_() : {0}".format(wcx.__next__()))
# 运行结果:
Traceback (most recent call last):
File "E:/GithubProject/MyProJect/JuniorLessons_beta/BigDataMicroMajor/Python/globalTest.py", line 8, in <module>
print("wcx._next_() : {0}".format(wcx.__next__()))
StopIteration
list(wcx) = []
filter
- filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
- 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
注意: Pyhton2.7 返回列表,Python3.x 返回迭代器对象,具体内容可以查看:Python3 filter() 函数
- 语法:
filter(function, iterable)
- function -- 判断函数。
- iterable -- 可迭代对象。
str
字符串
修饰符
使用 f 修饰符可以在字符串内支持大括号内的 python 表达式
Python replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
用法
str.replace(old, new[, max])
- old -- 将被替换的子字符串。
- new -- 新字符串,用于替换old子字符串。
- max -- 可选字符串, 替换不超过 max 次
- 返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次。
split()
Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
用法
str.split(str="", num=string.count(str)).
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。默认为 -1, 即分隔所有。
- 返回分割后的字符串列表。
注意:该方法不会改变原本的字符串
# 实例
str_t = "Line1-abcdef \nLine2-abc \nLine4-abcd"
print("str_t:\n"+str_t)
print("str_t.split():")
print(str_t.split()) # 以空格为分隔符,包含 \n
print("str_t.split(' ', 1):")
print(str_t.split(' ', 1)) # 以空格为分隔符,分隔成两个
# 运行结果
str_t:
Line1-abcdef
Line2-abc
Line4-abcd
str_t.split():
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
str_t.split(' ', 1):
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
join()
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
用法
str.join(sequence)
- sequence -- 要连接的元素序列。
- 返回通过指定字符连接序列中元素后生成的新字符串。
# 实例
str_t = ""
seq = ("a", "b", "c")
print(str_t.join(seq))
# 运行结果
abc
strip()
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符) 或字符序列。
- 注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
用法
str.strip([chars]);
- chars -- 移除字符串头尾指定的字符序列。
- 返回移除字符串头尾指定的字符生成的新字符串。
# 用法
str_t = "00000003210Runoob01230000000"
print(str_t.strip('0')) # 去除首尾字符 0
print()
str2 = " Runoob " # 去除首尾空格
print(str2.strip())
# 运行结果
3210Runoob0123
Runoob
lower()
Python lower() 方法转换字符串中所有大写字符为小写。
用法
str.lower()
- 返回将字符串中所有大写字符转换为小写后生成的字符串。
注意:此方法并不会改变原有列表,而是生成一个新列表
string 模块
import string
string.ascii_uppercase 所有大写字母
string.ascii_lowercase 所有小写字母
string.ascii_letters 所有字母
string.digits 所有数字
dict
- 字典是另一种可变容器模型,且可存储任意类型对象。
- 字典是无序的
- 字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 } - 键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
>>> dict = {'a': 1, 'b': 2, 'b': '3'} >>> dict['b'] '3' >>> dict {'a': 1, 'b': '3'} - 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
- 一个简单的字典实例:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'} - 也可如此创建字典:
dict1 = { 'abc': 456 } dict2 = { 'abc': 123, 98.6: 37 }
- 一个简单的字典实例:
访问字典里的值
把相应的键放入熟悉的方括弧,如下实例:
# 实例
dict1 = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print("dict1['Name']: ", dict1['Name'])
print("dict['Age']: ", dict1['Age'])
# 运行结果
dict1['Name']: Zara
dict['Age']: 7
items
- Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组。
- 用法
dict.items()- 返回值
- 返回可遍历的(键, 值) 元组数组。
- 返回值
- 示例
dict1 = {'Google': 'www.google.com', 'Runoob': 'www.runoob.com',
'taobao': 'www.taobao.com'}
print("字典值 : %s" % dict1.items())
# 遍历字典列表
for key, values in dict1.items():
print(key, values)
# 运行结果
字典值 : dict_items([('Google', 'www.google.com'), ('Runoob', 'www.runoob.com'), ('taobao', 'www.taobao.com')])
Google www.google.com
Runoob www.runoob.com
taobao www.taobao.com
修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下
# 实例
dict1 = {'Name': 'Zara', 'Age': 7, 'Class':'First'}
dict1['Age'] = 8 # 更新
dict1['School'] = "RUNOOB" # 添加
print("dict1['Age']: ", dict1['Age'])
print("dict1['School']: ", dict1['School'])
# 运行结果
dict1['Age']: 8
dict1['School']: RUNOOB
删除字典元素
- 能删单一的元素也能清空字典,清空只需一项操作。
- 删除一个字典用del命令
del dict['Name'] # 删除键是'Name'的条目
dict.clear() # 清空字典所有条目
del dict # 删除字典
字典键的特性
- 字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
- 两个重要的点需要记住:
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
- 键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行
文件操作
- 学习目标
- 熟练掌握内置函数open()的应用
- 理解字符串编码格式对文本文件操作的影响
- 熟练掌握上下文管理语句with的用法
- 了解标准库json对JSON文件的读写方法
- 了解扩展库python-docx、openpyxl、python-pptx对Office文档的操作
- python中的文件对象:
- 文件对象不仅可以用来访问普通的磁盘文件, 而且也可以访问任何其它类型抽象层面上的"文件".
- 一旦设置了合适的"钩子", 你就可以访问具有文件类型接口的其它对象, 就好像访问的是普通文件一样.
文件与文件类型
- 文件是存储在外部介质上的一组相关数据的集合。文件的基本单位是字节。文件名由两部分组成:主文件名和扩展名
- 按文件中的数据组织形式文件分为两类:
- 文本文件
- 由字符组成,按ASCII码、UTF-8或Unicode等格式编码,文件内容方便查看和编辑。
- 二进制文件
- 由0和1组成的二进制编码。典型的二进制文件包括bmp格式的图片文件、avi格式的视频文件、各种计算机语言编译后生成的文件等。
- 无论是文本文件还是二进制文件,都可以用“文本文件方式”和“二进制文件方式”打开,但打开后的操作是不同的。
- 文本文件
csv文件
- .csv是一种文件格式(如.txt、.doc等) ,也可理解.csv文件就是一种特殊格式的纯文本文件。即是一组字符序列,字符之间已英文字符的逗号或制表符(Tab) 分隔。
字符编码
- 编码是用数字来表示符号和文字的一种方式,
- 是符号、文字存储和显示的基础。
- 信息传递与编码关系:编码--传递--解码
- 常见的编码
- ASCII 美国标准信息交换码
- (1个字节,256个字符)
- UTF-8 国际通用编码
- (3个字节表示中文及其他语言)
- GB2312 中国制定的中文编码
- (英文1个字节,中文2个字节)
- GBK GB2312编码的扩展
- 完全兼容GB2312标准
- Unicode
- 国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
- ASCII 美国标准信息交换码
- 字符串在Python内部的表示是unicode编码
- 因此,在做编码转换时,通常需要以unicode作为中间编码,
- 即先将其他编码的字符串解码(decode) 成unicode,
- 再从unicode编码(encode) 成另一种编码。
- 因此,在做编码转换时,通常需要以unicode作为中间编码,
- decode的作用是将其他编码的字符串转换成unicode编码
- 表示将gb2312编码的字符串str1转换成unicode编码。
str1.decode('gb2312')
- encode的作用是将unicode编码转换成其他编码的字符串
- 表示将unicode编码的字符串str2转换成gb2312编码。
str2.encode('gb2312')
- 如:s='中文'
- 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。
- 这种情况下,要进行编码转换,都需要先用decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。
- 通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。如下:
s.decode('utf-8').encode('utf-8')
- 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。
- decode():是解码
- encode()是编码
- isinstance(s,unicode): 判断s是否是unicode编码,如果是就返回true,否则返回false
文件操作基础
内置函数open()
- Python内置函数open()使用指定的模式打开指定文件并创建文件对象,该函数完整的用法如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
| 模式 | 说明 |
|---|---|
| r | 读模式(默认模式,可省略) ,如果文件不存在,抛出异常 |
| w | 写模式,如果文件已存在,先清空原有内容;如果文件不存在,创建新文件 |
| x | 写模式,创建新文件,如果文件已存在则抛出异常 |
| a | 追加模式,不覆盖文件中原有内容 |
| b | 二进制模式(可与r、w、x或a模式组合使用) |
| t | 文本模式(默认模式,可省略) |
| + | 读、写模式(可与其他模式组合使用) |
文件对象常用方法
| 方法 | 功能说明 |
|---|---|
| close() | 把缓冲区的内容写入文件,同时关闭文件,释放文件对象 |
| read([size]) | 从文本文件中读取并返回size个字符,或从二进制文件中读取并返回size个字节,省略size参数表示读取文件中全部内容 |
| readline() | 从文本文件中读取并返回一行内容 |
| readlines() | 返回包含文本文件中每行内容的列表 |
| seek(cookie, whence=0, /) | 定位文件指针,把文件指针移动到相对于whence的偏移量为cookie的位置。其中whence为0表示文件头,1表示当前位置,2表示文件尾。对于文本文件,whence=2时cookie必须为0;对于二进制文件,whence=2时cookie可以为负数 |
| write(s) | 把s的内容写入文件,如果写入文本文件则s应该是字符串,如果写入二进制文件则s应该是字节串 |
| writelines(s) | 把列表s中的所有字符串写入文本文件,并不在s中每个字符串后面自动增加换行符。也就是说,如果确实想让s中的每个字符串写入文本文件之后各占一行,应由程序员保证每个字符串以换行符结束 |
上下文管理语句with
- 在实际开发中,读写文件应优先考虑使用上下文管理语句with。关键字with可以自动管理资源,不论因为什么原因跳出with块,总能保证文件被正确关闭。除了用于文件操作,with关键字还可以用于数据库连接、网络连接或类似场合。用于文件内容读写时,with语句的语法形式如下:
with open(filename, mode, encoding) as fp: # 这里写通过文件对象fp读写文件内容的语句块
文件的打开或创建的访问模式
#以只读方式打开
>>> file2=open(“c1.py”,”r”)
#以读/写方式打开,指明文件路径
>>> file3=open(“d:\\python35\\test.txt”,”w+”)
#以读/写方式二进制文件
>>> file4=open(“tu3.jpg”,”ab+”)
import os
file_path = os.path.abspath(os.path.join(os.path.dirname(__file__), './res/files/myData.txt'))
with open(file_path, 'r', encoding='GBK') as f:
my1 = f.read(9)
my2 = f.readline() # 从当前指针处读写
my3 = f.readlines()
print("f.read(9):", my1)
print("f.readline():", my2)
print("f.readlines():", my3)
f.close()
### 执行结果:
f.read(9): learn pyt
f.readline(): hon
f.readlines(): ['hard work\n', '文本文件\n', '二进制文件']
CSV文件
- CSV文件是一种文本文件,由任意数目的行组成,一行被称为一条记录。
- CSV格式存储的文件一般采用.csv为扩展名,
- 可以记事本或微软 Excel工具打开,可以在其他操作系统平台上用文本编辑工具打开。
- CSV文件特点如下
- 读取出的数据一般为字符类型,如果要获得数值类型,需要用户完成转换。
- 以行为单位读取数据。
- 列之间以半角逗号或制表符为分隔,一般为半角逗号。
- 一般为每行开头不空格,第一行是属性列,数据列之间用间隔符分隔,无空格,行之间无空行。
csv库
- Python提供了一个读写CSV文件的标准库,可以通过 import csv语句导入。
- csv库包含了操作CSV格式文件最基本的功能,典型的方法是csv.reader()和csv.writer(),分别用于读和写CSV文件。
向CSV文件中写入和读取数据
- 用列表变量保存数据,可以使用字符串的join()方法组成逗号分隔形式,再通过文件的write()方法保存到CSV文件中。
- 读取CSV文件中的数据,即读取一行数据,使用文件的read()方法读取即可,也可以将文件的内容读取到列表中。
异常处理
异常的概念
- 异常(Exception) 就是程序在运行过程中发生的,由于硬件故障、软件设计错误、运行环境不满足等原因导致的程序错误。
- 比如网络中断、文件找不到等
- 代码运行时如果发生了异常,将生成代表该异常的一个对象,并交由Python解释器寻找相应的代码来处理这一异常。
- Python异常处理优点
- 异常处理代码和正常执行的程序代码分离
- 多个异常统一处理,具有灵活性
- 可以从try-except之间的代码段中快速定位异常出现的位置
示例
weekday = ["Mon", "Tues", "Weds", "Thurs", "Fri", "Sat", "Sun"]
print(weekday[2])
print(weekday[7])
# 执行结果:
Weds
Traceback (most recent call last):
File "E:/GithubProject/MyProJect/JuniorLessons_beta/BigDataMicroMajor/Python/globalTest.py", line 3, in <module>
print(weekday[7])
IndexError: list index out of range
try:
weekday = ["Mon", "Tues", "Wed", "Thurs", "Fri", "Satur", "Sun"]
print(weekday[2])
print(weekday[7])
except IndexError:
print("列表索引可能超出范围")
# 运行结果:
Wed
列表索引可能超出范围
异常类型
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| SystemExit | Python 解释器请求退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有没有此索引(index)【越界】 |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
异常处理机制
- 程序执行过程中如果出现异常,会自动生成一个异常对象,该异常对象被提交给Python解释器,这个过程称为抛出异常。抛出异常也可以由用户程序自行定义。
- 当Python解释器接收到异常对象时,会寻找处理这一异常的代码并处理,这一过程叫捕获异常。
- 如果Python解释器找不到可以处理异常的方法,则运行时系统终止,应用程序退出。
try-except语句
- 用于处理异常,帮助用户准确定位异常发生的位置和原因。
- 格式如下
try: 语句块 except ExceptionName1: 异常处理代码1 except ExceptionName2: 异常处理代码2 ……
try语句
- 指定捕获异常的范围,由try所限定的代码块中的语句在执行过程中,可能会生成异常对象并抛出。
except语句
- 每个try代码块必须有一个或多个except语句,用于处理try代码块中所生成的异常。
- except语句后的参数指明它能够捕获的异常类型。except块中包含的是异常处理的代码。
- 示例:
while True: try: x = int(input("请输入数据")) print(100/x) except ZeroDivisionError: print("异常信息:除数不能为0") except ValueError: print("异常信息:输入数据必须是阿拉伯数字") # 运行结果: 请输入数据0 异常信息:除数不能为0 请输入数据s 异常信息:输入数据必须是阿拉伯数字 请输入数据11.1 异常信息:输入数据必须是阿拉伯数字
else语句和finally语句
- 完整的异常处理结构还可以包括else语句和finally语句。
try:
语句块
except ExceptionName:
异常处理代码
…… # except可以有多条语句
else:
无异常发生时的语句块
finally:
必须处理的语句块
else语句
- 与循环中的else语句类似,当try语句没有捕获到任何异常信息,将不执行except语句块,而是执行else语句块。
finally语句
- 为异常处理提供一个统一的出口,使得在控制流转到程序的其他部分以前,能够对程序的状态作统一的管理。
- 不论在try代码块中是否发生了异常,finally块中的语句都会被执行。
示例
- 从键盘输入一个整数,求100除以它的商,并显示。
- 对从键盘输入的数进行异常处理,若无异常发生,打印提示信息。
while True:
try:
x = int(input("请输入数据"))
print(100 / x)
except ZeroDivisionError:
print("异常信息:除数不能为0")
except ValueError:
print("异常信息:输入数据必须是阿拉伯数字")
else:
print("程序正常结束,未捕获到异常")
# 运行结果:
请输入数据0
异常信息:除数不能为0
请输入数据11.1
异常信息:输入数据必须是阿拉伯数字
请输入数据5
20.0
程序正常结束,未捕获到异常
请输入数据
fName = "program0805.py"
file = None
try:
file = open(fName, "r", encoding="utf-8")
for line in file:
print(line, end="")
except FileNotFoundError:
print("您要读取的文件不存在,请确认")
else:
print("文件读取正常结束")
finally:
print("文件正常关闭")
if file != None:
file.close()
# 运行结果:
您要读取的文件不存在,请确认
文件正常关闭
建站工具
Reflex
Mark: 适用于需要给当前项目做个基本展示页面不想直接上前端框架的情况, 直接拿 python 生成网页应用程序
使用 http.server 搭建文件服务器
simple-https-server.py --- simple-https-server.py (github.com)
simple-https-server.py --- simple-https-server.py (github.com)
最基础的用法, 使用如下命令可以在本机 8000 端口起一个文件服务器
python -m http.server
要结合 ssl 的话需要先创建一组密钥, 可以参考 此处 生成ca根证书密钥对并签发这里的证书与密钥对, 然后将根证书添加到本地受信任的根证书颁发机构
然后创建一个 py 文件, 如 https_server.py:
from http.server import HTTPServer, SimpleHTTPRequestHandler
import ssl
from pathlib import Path
server_address = ("0.0.0.0", 443)
PEM_PATH = Path(__file__).parent / "key/py-server/summer-py-server.crt"
KEY_PATH = Path(__file__).parent / "key/py-server/summer-py-server.key"
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
httpd.socket = ssl.wrap_socket(
httpd.socket,
certfile=PEM_PATH,
keyfile=KEY_PATH,
server_side=True,
ssl_version=ssl.PROTOCOL_TLS,
)
httpd.serve_forever()
python https_server.py
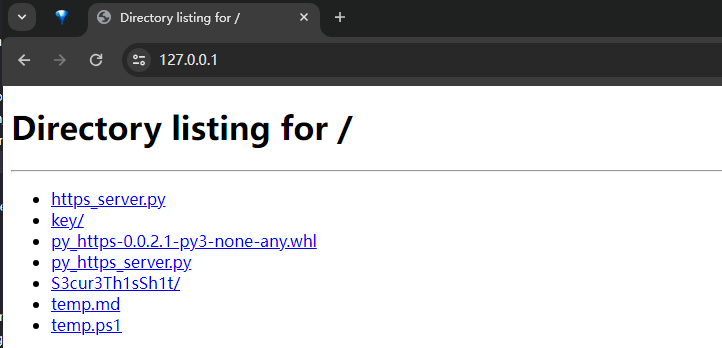
DNS Server
报错收集
no module named ‘pip’
一般出现在更新 pip 显示无权访问后出现(因为更新前会先卸载旧版本pip, 安装新版本时出错就导致了 pip缺失)
可以使用 python -m ensurepip 重装 pip
然后会提示删掉 site_packages 中的 ~ip 等以 ~ 开头的文件(夹), 因为这些文件都是没有安装成功的包