sovits-32k 使用随笔
sovits-32k 使用随笔
最近看了许多 AI 翻唱, 感觉很有意思, 遂开新坑
环境搭建
sovits 依赖中包含 numpy==1.19.2, 支持 Python 3.6-3.8, 这里选择了创建了一个 3.8.16 的 conda 环境
安装 CUDA
深度学习GPU环境CUDA详细安装过程(简单快速有效) - 知乎 (zhihu.com)
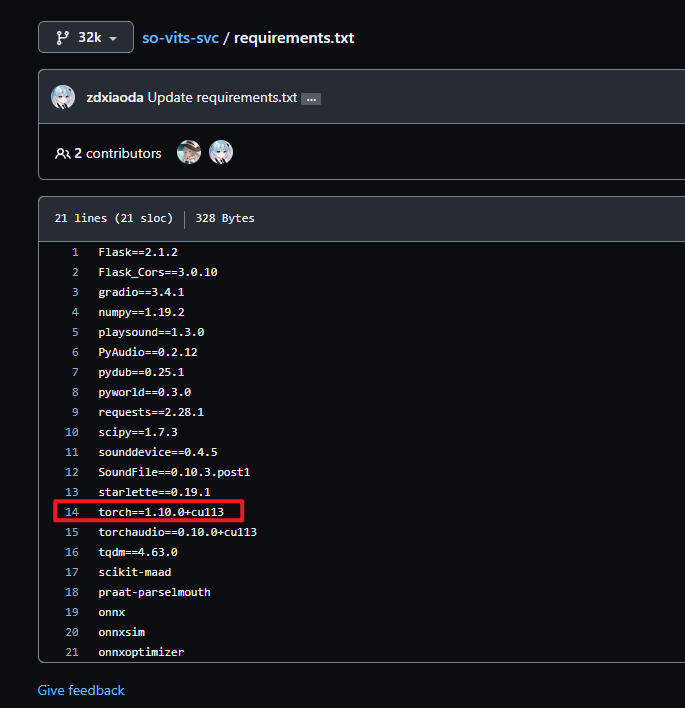
需要注意的是 requirements.txt Line14 torch==1.10.0+cu113, 表示应当安装 CUDA11.3, 不要直接装了官网最新的 CUDA 12.0
CUDA Toolkit 11.3 Downloads | NVIDIA Developer (这个版本依旧行不通)
这个也不对 , 虽然依赖里是
torch==1.10.0+cu113, 但是到训练那一步时始终卡在
参考下 sovits3.0一键脚本(小狼躺平了,所以是深夜诗人修改版本,已更新32k/48k分支切换) .ipynb - Colaboratory (google.com)
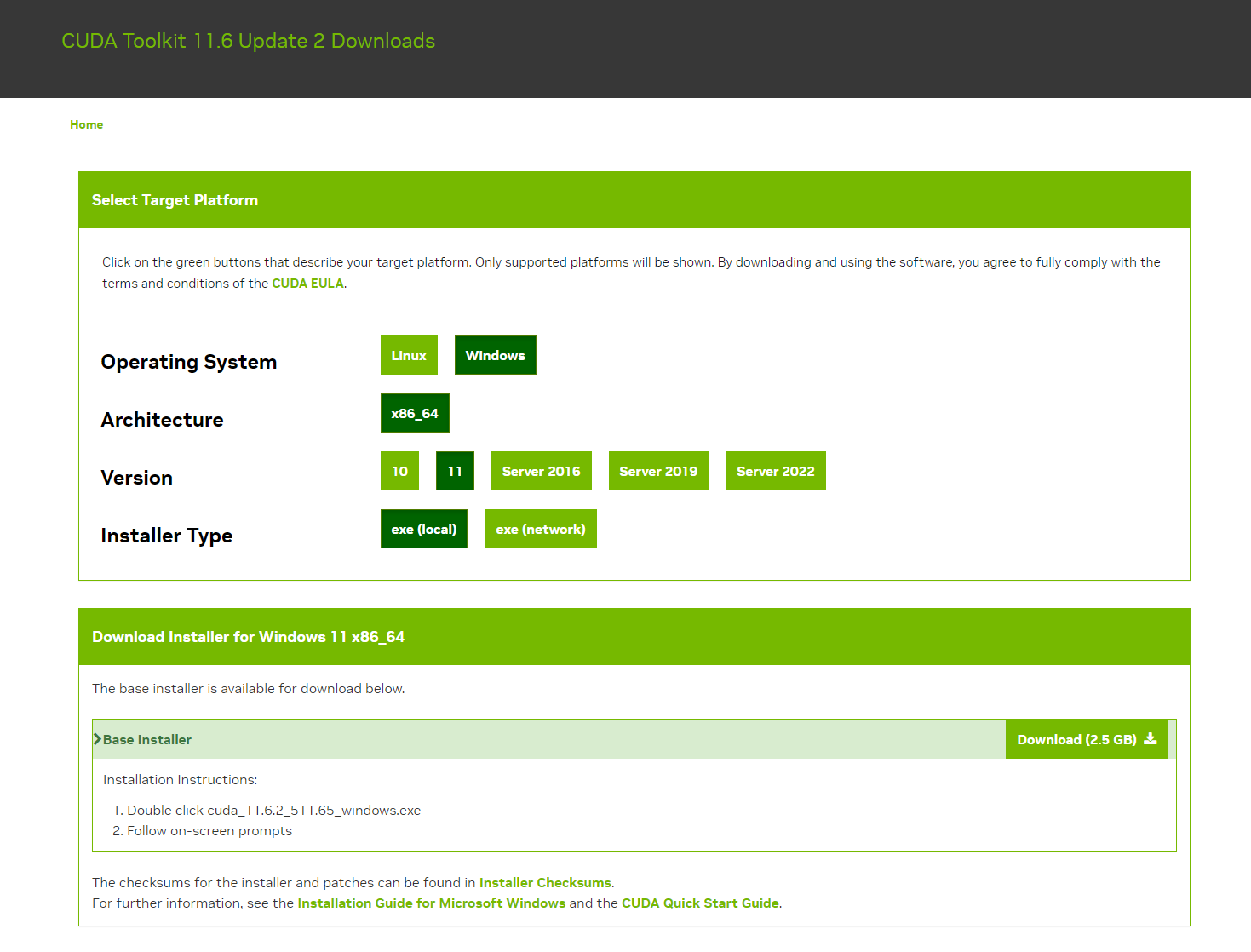
CUDA Toolkit 11.6 Update 2 Downloads | NVIDIA Developer
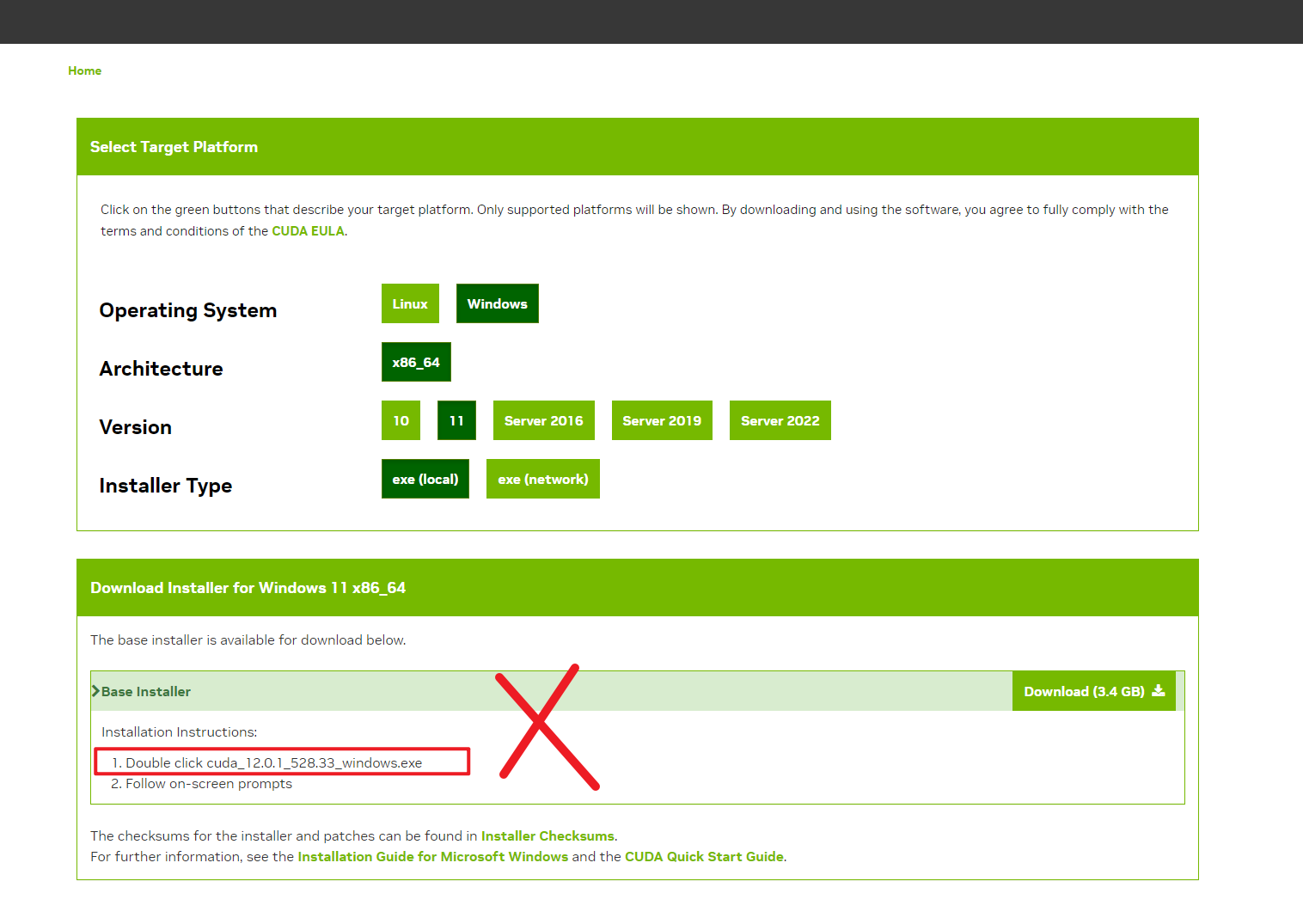
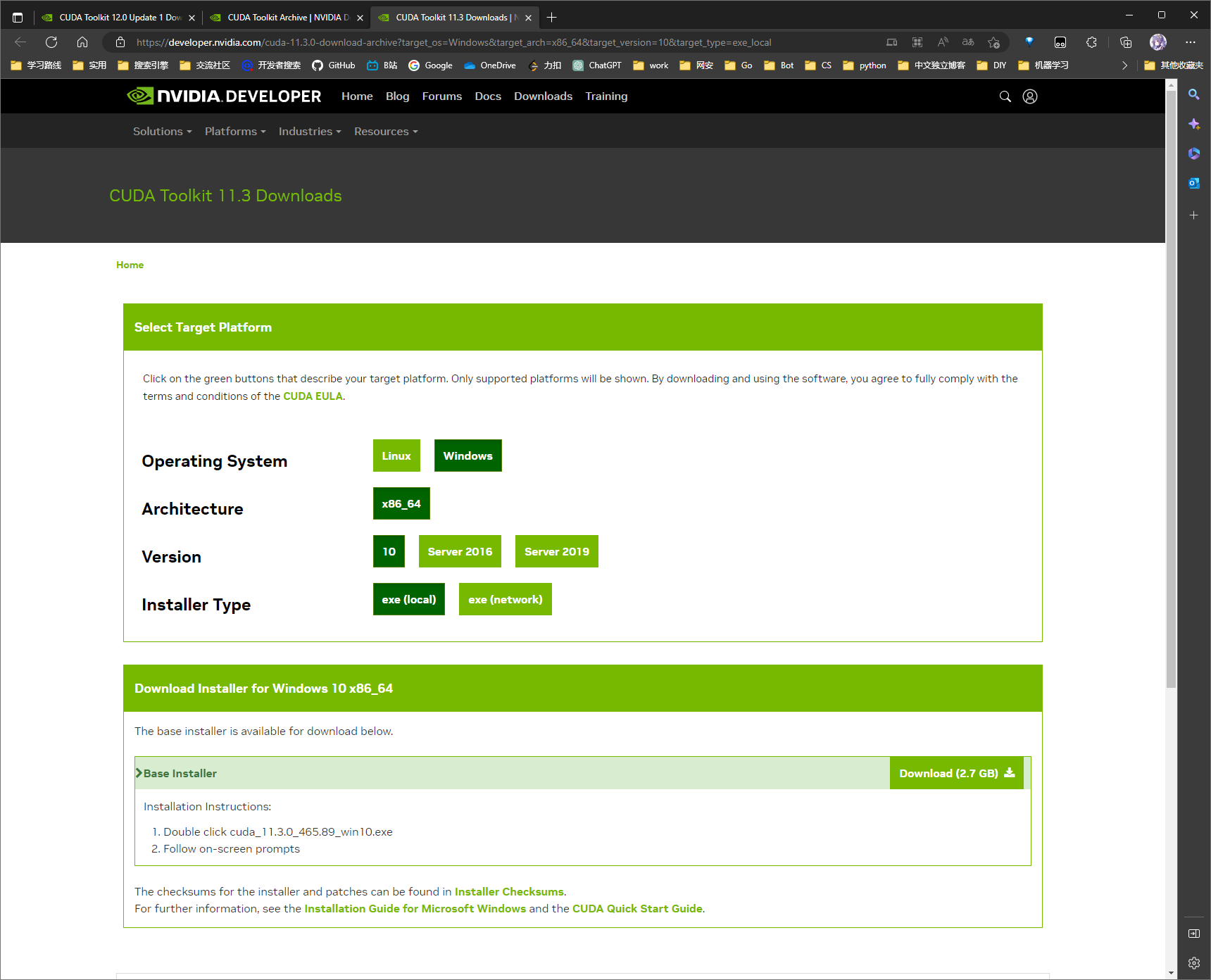

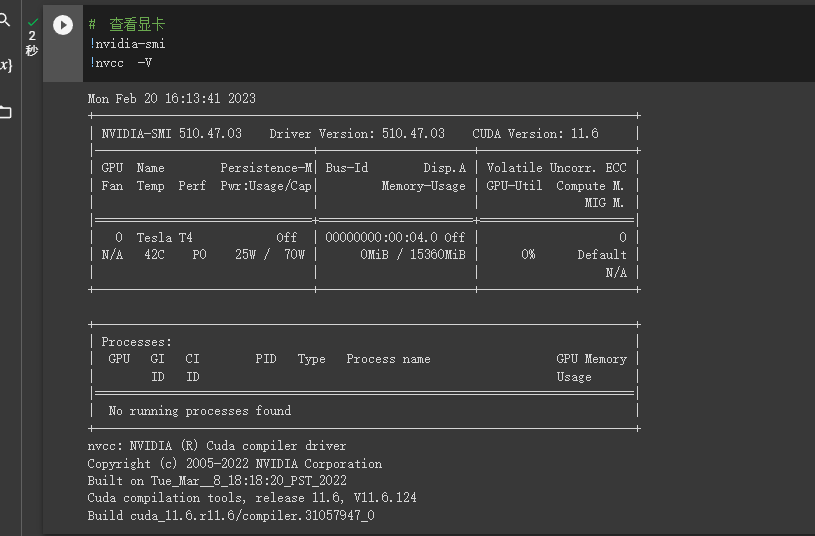
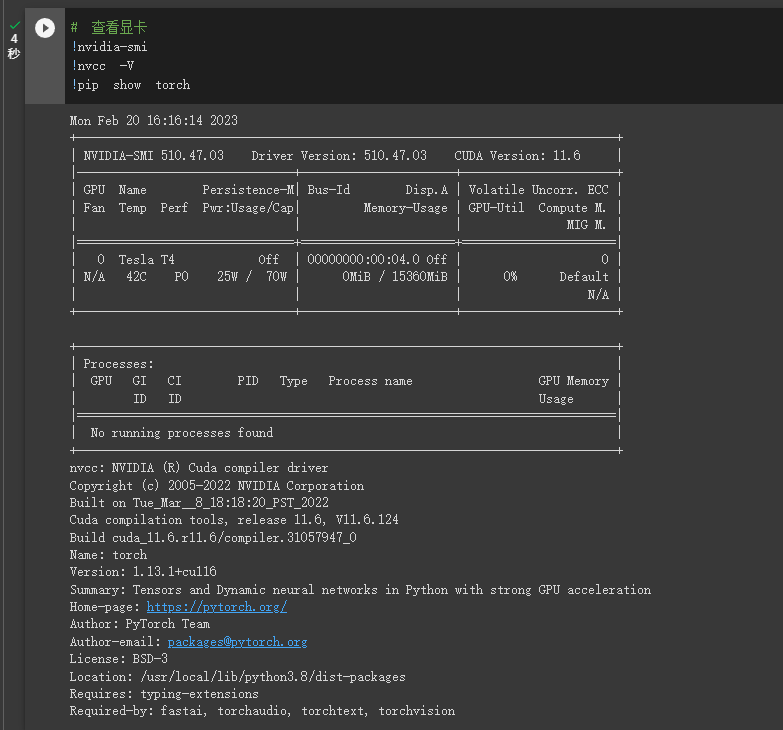
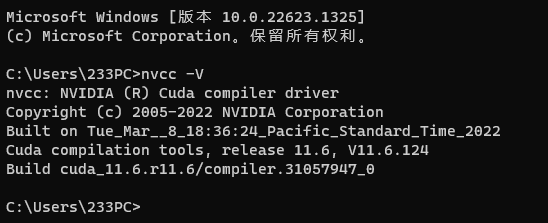
安装完成后测试是否安装成功:
下载 CUDNN 解压并将 bin、include、lib文件直接复制到CUDA的安装目录下
安装依赖
pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple/
使用清华源的话会在安装
torch==1.10.0+cu113时因找不到对应版本而报错(虽然使用官方源我也没找到)
按照 soVITS3.0炼丹Bug Solve - 哔哩哔哩 (bilibili.com) 中的方案访问 PyTorch官网
Previous PyTorch Versions | PyTorch Start Locally | PyTorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia虽然
requirements.txt中是torch1.10+cu113但是实测该 torch 版本在最后训练时即便装了 tensorboard 2.11.2 依旧无法正常运行这一步可能会卡在
sloving environment很长时间, 睡一觉即可解决问题(bush, 总之放一边装依赖就可以了, 可能会花很久然后把
requirements.txtline 14~15的torch==1.10.0+cu113 torchaudio==0.10.0+cu113删掉然后重新
pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple/



拉取 sovits 仓库并下载放置模型文件
# 拉取了默认的 32khz 分支
git clone https://github.com/innnky/so-vits-svc.git
cd so-vits-svc
# hubert
wget -P hubert/ https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt
# G与D预训练模型
wget -P logs/32k/ https://huggingface.co/innnky/sovits_pretrained/resolve/main/G_0.pth
wget -P logs/32k/ https://huggingface.co/innnky/sovits_pretrained/resolve/main/D_0.pth
准备素材
最近在推近月少女的礼仪, luna sama 简直是天使(浓度是不是有点高了(), 因此打算用游戏语音炼个丹, 首先遇到的问题就是如何获取到角色的 wav 语音文件
尝试用 AssetStudio 解包官方 Steam 国际中文版的安装目录最终解出了标题页和 Config 的语音, 不过剧情角色语音无法解除来, 使用其他工具亦无果, 最终翻找了找往期汉化组封包的版本找到了若干 pack 文件, 使用 GARbro 成功解出了若干 ogg
解包后语音文件非常多, 使用人工辨识 + 语音文件中的特殊字符串将每个角色的语音都分开存放, 最终得到了 1151 个露娜的语音文件以及 6916 个朝日的语音文件, 尤希, 凑和瑞穗差不多都是将近 600 个语音文件, 里想奈 300 多, 游星不到 100 以及 1600 多个幼年游星的语音文件(
以朝日的一个语音文件为例
ap_v_asa0001.ogg, 其中asa就是指asahi, 还是比较好区分的, 将所有文件按照字典序排列之后即使是手工分类也并没有耗费太多时间
ogg 与 wav 主要有如下区别
- 编码方式不同:WAV使用PCM编码,而OGG使用Ogg Vorbis编码。PCM编码是无损编码,但文件体积大,音质好;Ogg Vorbis是有损编码,可以压缩文件大小,但音质稍差。
- 文件大小:由于编码方式不同,同样长度的音频文件,OGG文件通常比WAV文件小。
- 支持的播放器:WAV是Windows系统上常见的音频格式,通常可以在大多数音频播放器上播放。但OGG格式在某些设备和操作系统上可能需要下载插件才能播放。
- 开源性:WAV是一种开放格式,但是由于它的大文件大小,WAV不适合在互联网上传输,也不适合流媒体传输。而OGG格式是一种自由开放的音频格式,适用于互联网上的音频传输。
音质上来讲 wav > flac > ogg > mp3 > wma
由于提取出来的文件均为 ogg 格式, 因此需要转换成 wav 格式, 这里使用了 ffmpeg 来进行处理, 例如:
ffmpeg -i inputfile.ogg outputfile.wav
由于朝日的语音文件比较多, 因此首先尝试用朝日的语音文件试试
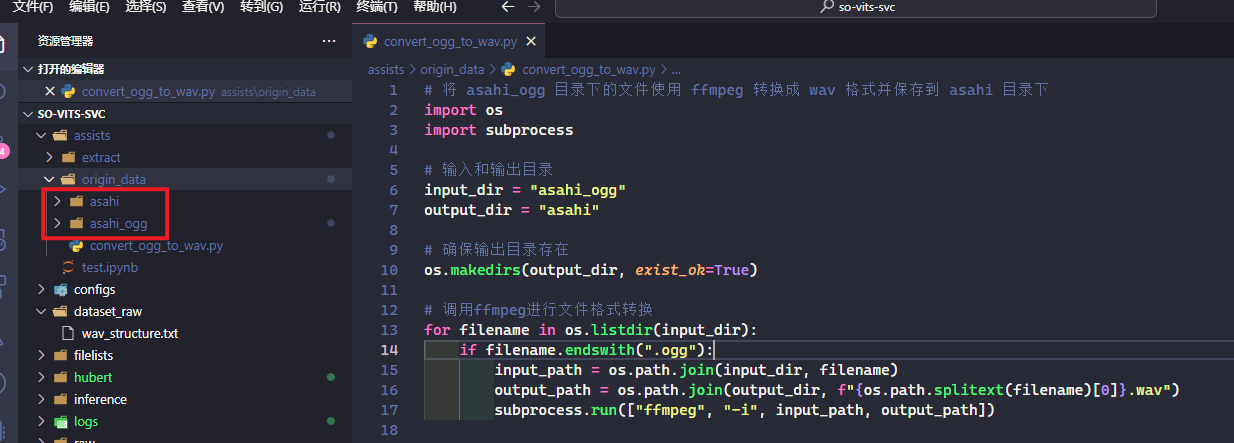
# 将 asahi_ogg 目录下的文件使用 ffmpeg 转换成 wav 格式并保存到 asahi 目录下
import os
import subprocess
# 输入和输出目录
input_dir = "asahi_ogg"
output_dir = "asahi"
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 调用ffmpeg进行文件格式转换
for filename in os.listdir(input_dir):
if filename.endswith(".ogg"):
input_path = os.path.join(input_dir, filename)
output_path = os.path.join(output_dir, f"{os.path.splitext(filename)[0]}.wav")
subprocess.run(["ffmpeg", "-i", input_path, output_path])
虽然变大了但是音质并不会有改善(甚至似乎可能会降低)
转换完成后将其剪切到了 dataset_raw 目录下:
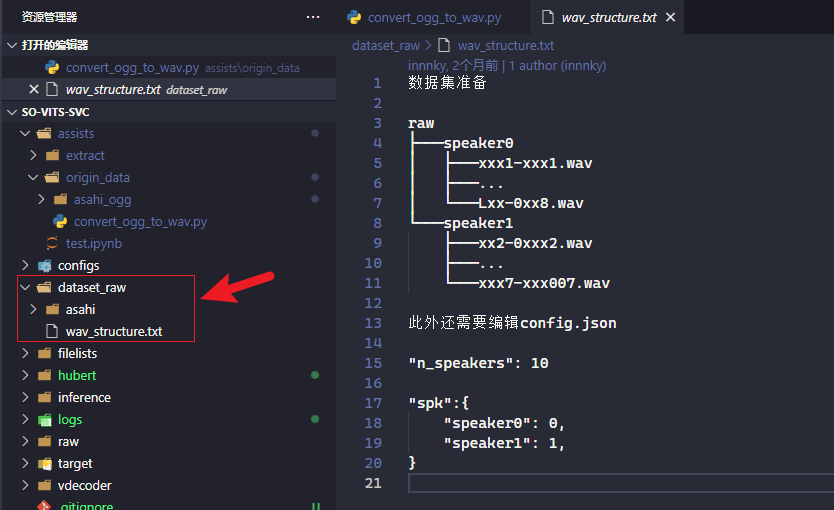
数据预处理
重新采样至 32khz
使用
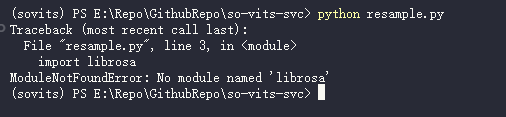
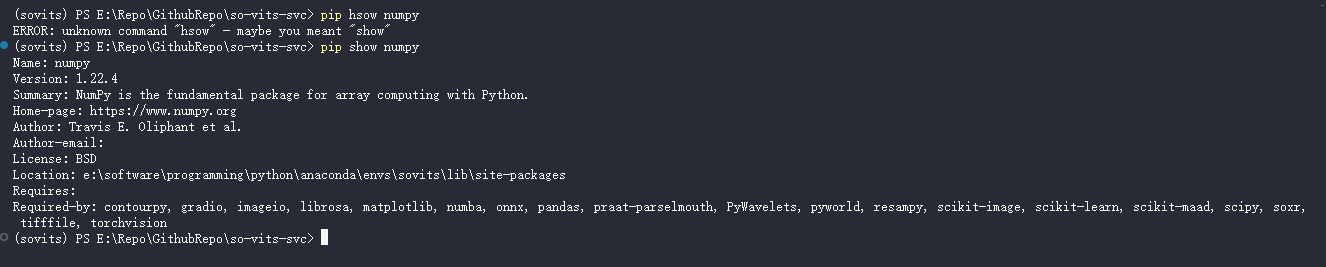
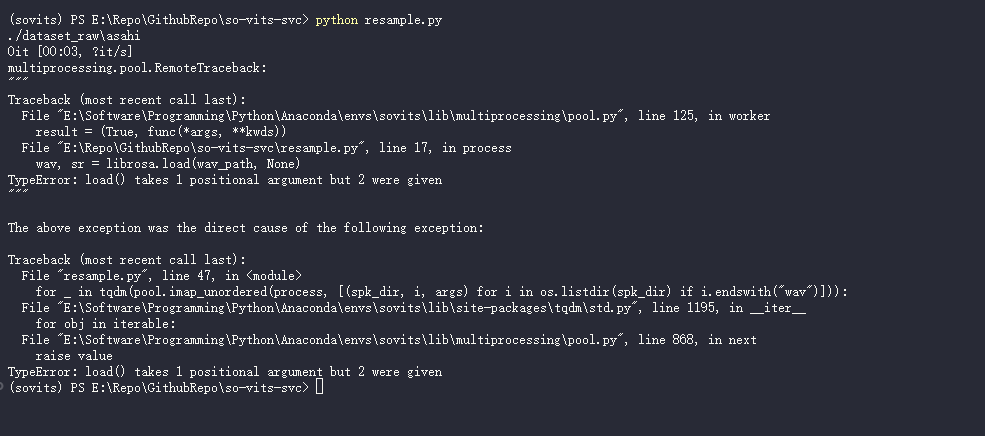
python resample.py
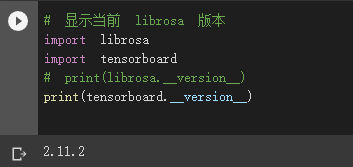
居然还会少依赖, 感觉有点没底, 手动装下
pip install librosa -i https://pypi.mirrors.ustc.edu.cn/simple/
好, 版本开始偏差了, 希望人没事(
重新
python resample.py
寄
重新
pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple/
哈哈,寄
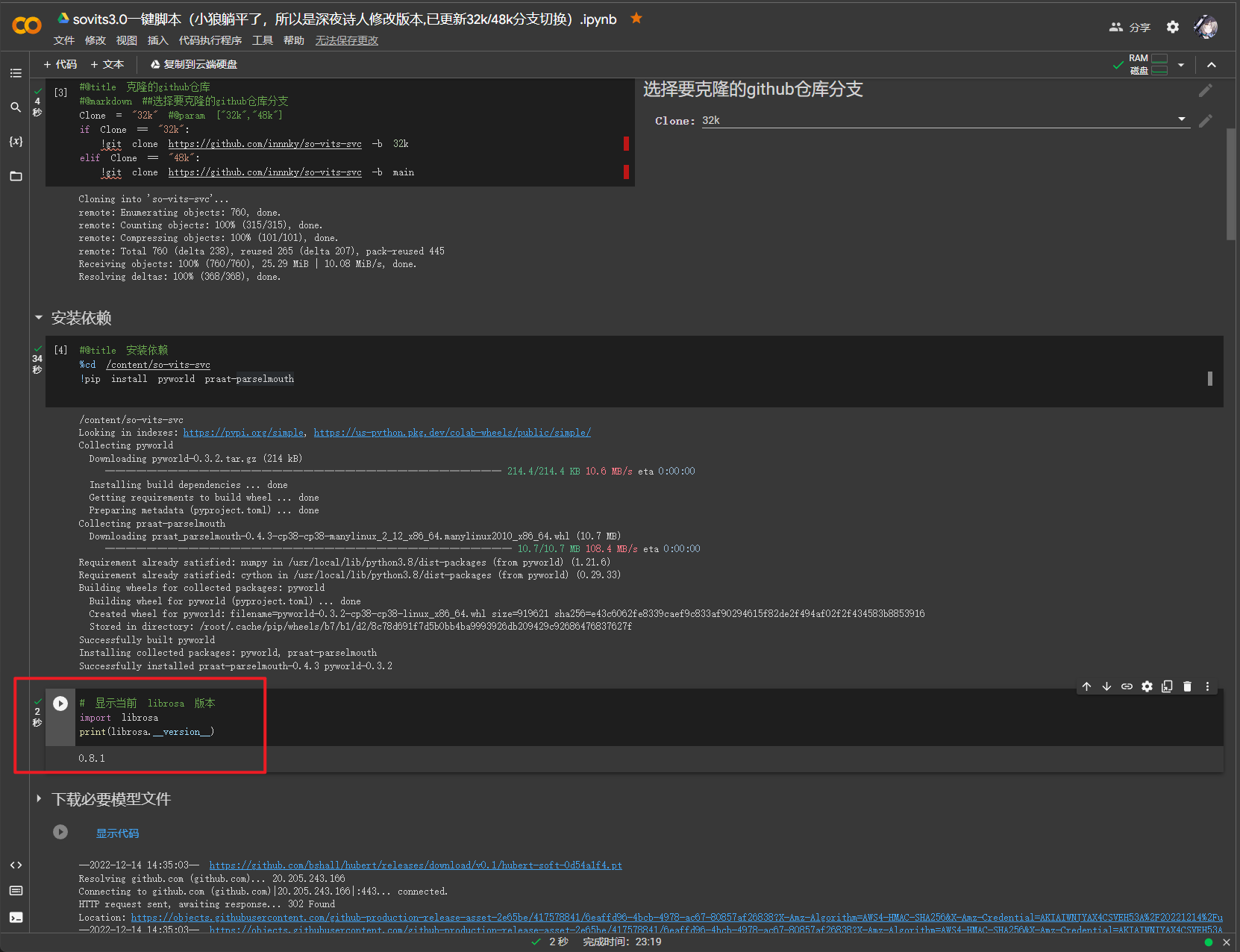
翻看下 sovits3.0一键脚本(小狼躺平了,所以是深夜诗人修改版本,已更新32k/48k分支切换) .ipynb - Colaboratory (google.com) 看看这里用的什么版本
尝试安装
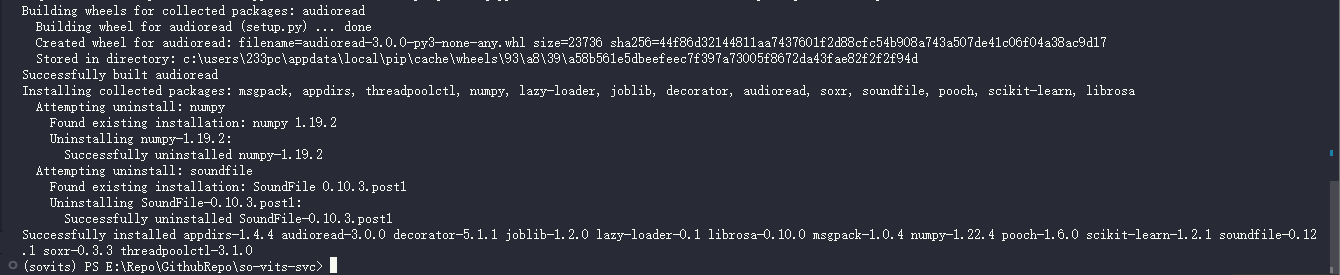
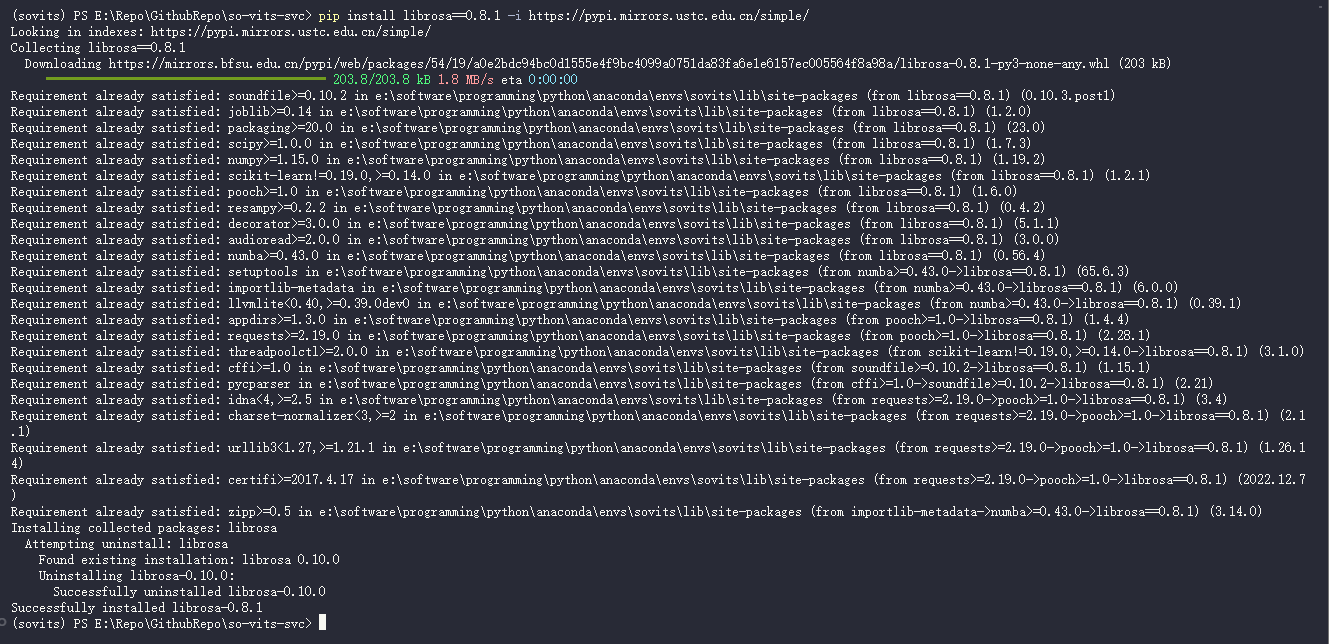
pip install librosa==0.8.1 -i https://pypi.mirrors.ustc.edu.cn/simple/
然后重新
pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple/
看样子没有问题了
尝试重新运行
python resample.py
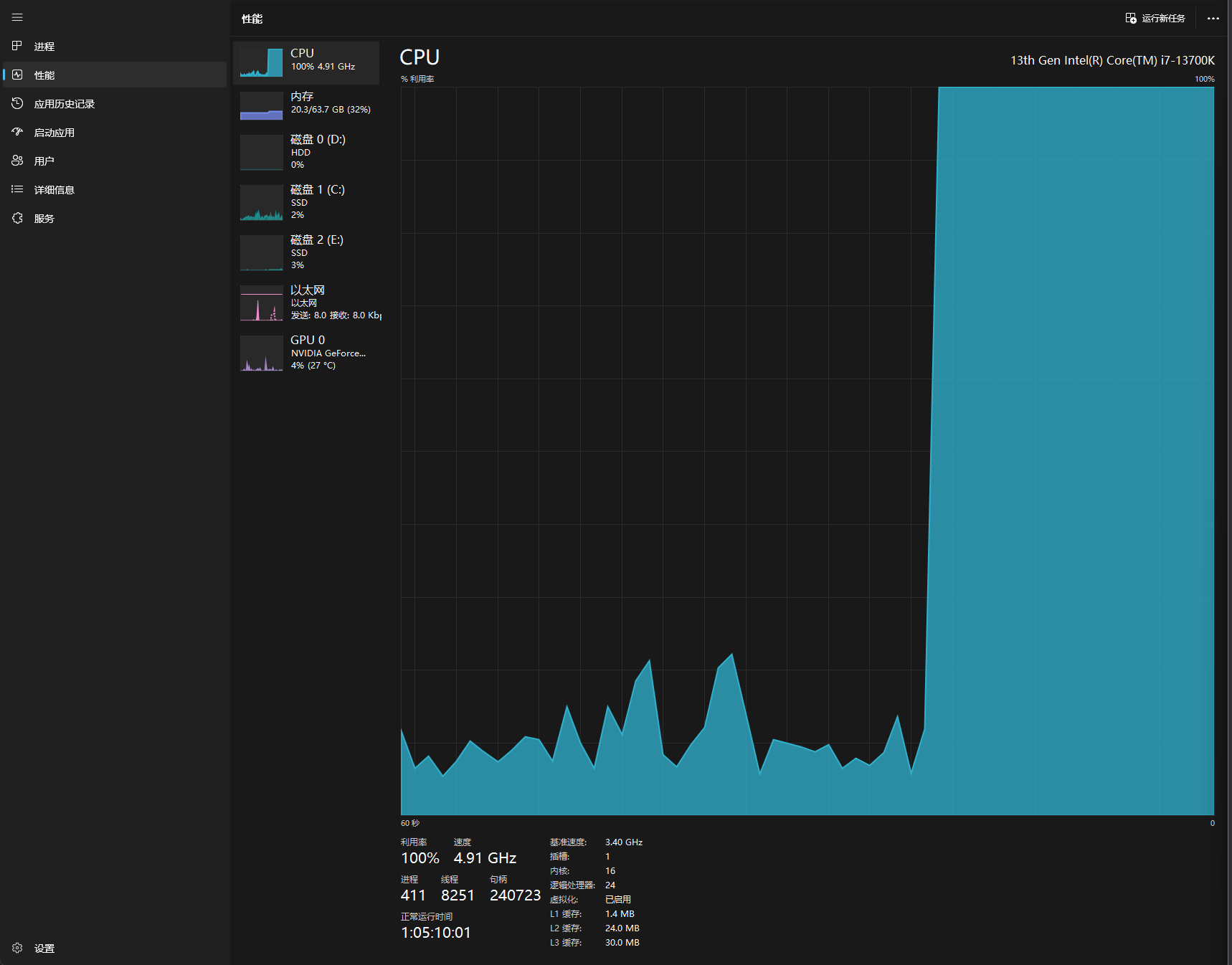
似乎正常跑起来了, 就是这个占用有点恐怖
就当无事发生.jpg(


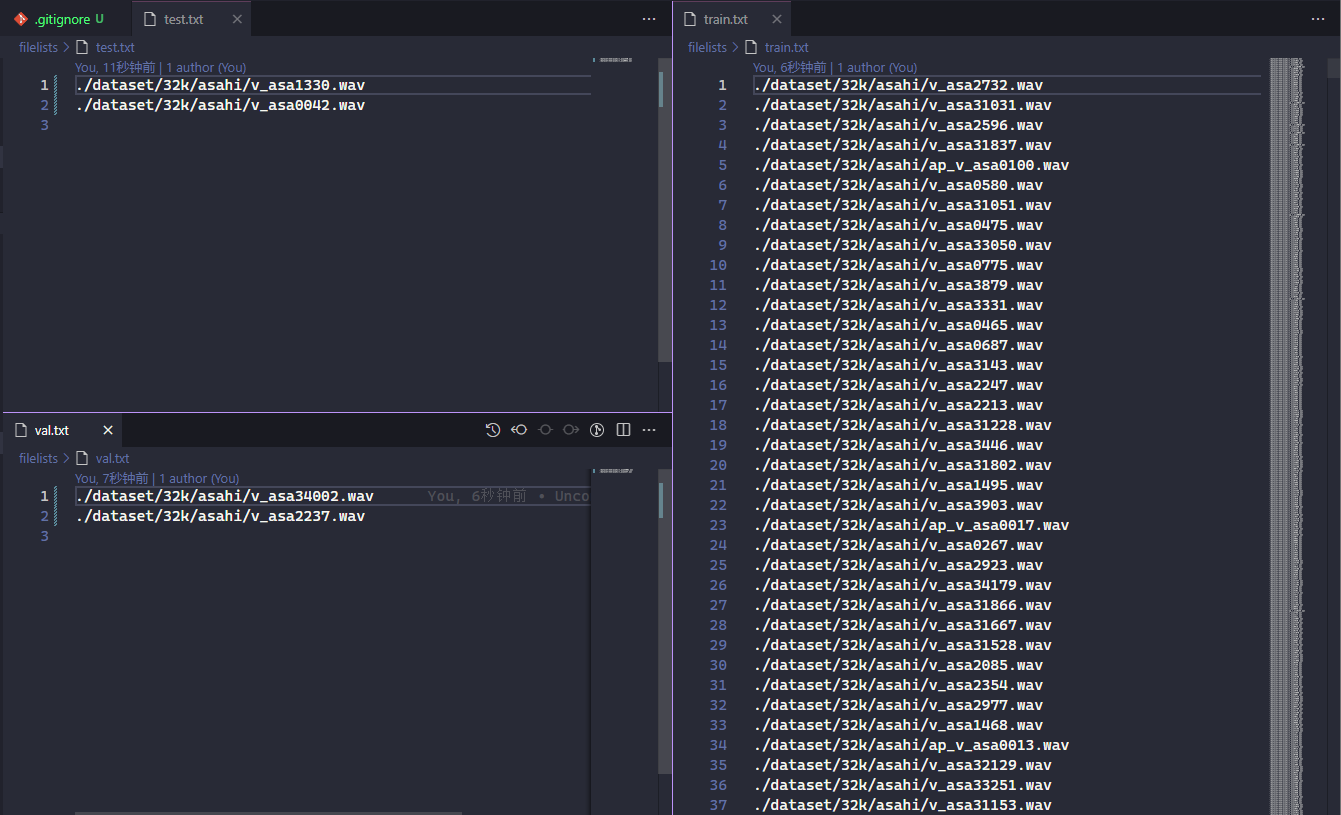
自动划分训练集 验证集 测试集 以及自动生成配置文件
python preprocess_flist_config.py
# 注意
# 自动生成的配置文件中,说话人数量n_speakers会自动按照数据集中的人数而定
# 为了给之后添加说话人留下一定空间,n_speakers自动设置为 当前数据集人数乘2
# 如果想多留一些空位可以在此步骤后 自行修改生成的config.json中n_speakers数量
# 一旦模型开始训练后此项不可再更改

生成hubert与f0
python preprocess_hubert_f0.py
训练
python train.py -c configs/config.json -m 32k
又缺库, 那继续参考 sovits3.0一键脚本(小狼躺平了,所以是深夜诗人修改版本,已更新32k/48k分支切换) .ipynb - Colaboratory (google.com)
pip install tensorboard==2.11.2 -i https://pypi.mirrors.ustc.edu.cn/simple/
重新
python train.py -c configs/config.json -m 32k
悲, 看看有没有其他版本
pip install tensorboard== -i https://pypi.mirrors.ustc.edu.cn/simple/
装下 12.0 试试
pip install tensorboard==2.12.0 -i https://pypi.mirrors.ustc.edu.cn/simple/
重新
python train.py -c configs/config.json -m 32k
悲, 试试 11.0
pip install tensorboard==2.11.0 -i https://pypi.mirrors.ustc.edu.cn/simple/
重新
python train.py -c configs/config.json -m 32k
开始怀疑是 torch 版本的问题了
是一致的
继续薅下 sovits3.0一键脚本(小狼躺平了,所以是深夜诗人修改版本,已更新32k/48k分支切换) .ipynb - Colaboratory (google.com):
🤣 我的问题, 难搞, 在重搞之前先再试试降下 tensorboard 版本(不过如果是通过 torch 调用的话估计没啥用)
pip install tensorboard==2.10.0 -i https://pypi.mirrors.ustc.edu.cn/simple/
降级不动了, 那估计要重新搞了, 先在 colab 上泡泡试试吧
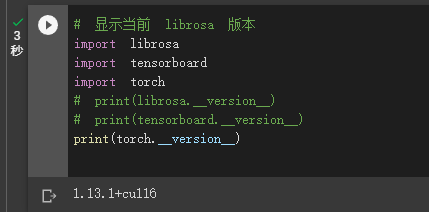
更新: 最终与 Colab 脚本保持一致, 使用 Torch 1.13.1 + CUDA 11.6 成功训练了模型






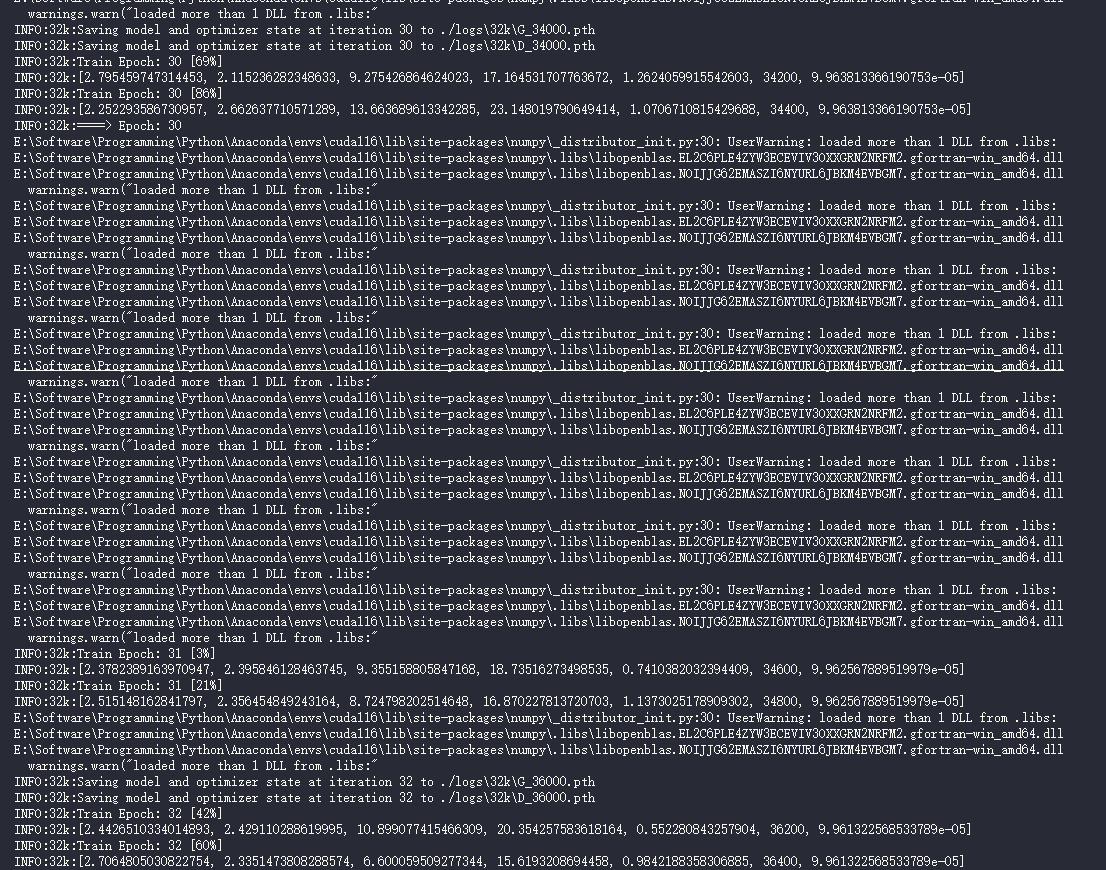
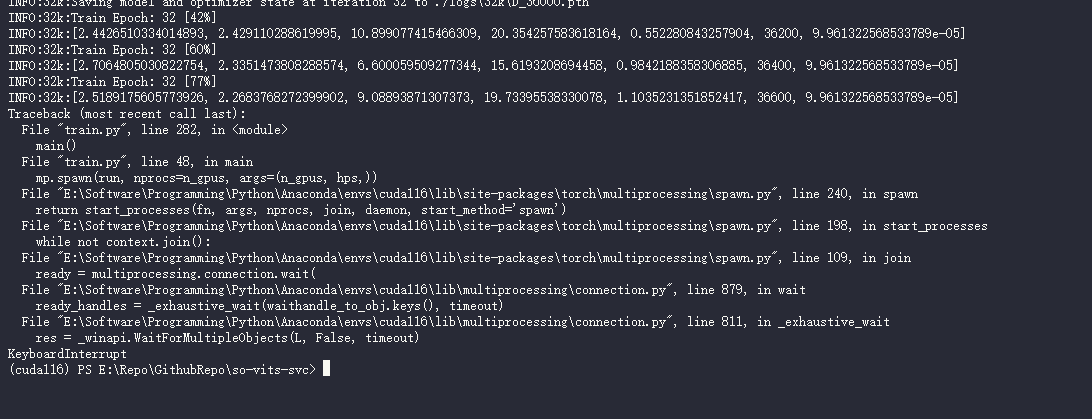
如果要停止训练的话可以直接 Ctrl + C, 下次训练会自动加载上一个保存的 checkpoint
3070Ti 跑了 12h 只跑了 30 个不到的 epoch, 先试试推理(
推理
准备人声+BGM
在 Releases · Anjok07/ultimatevocalremovergui (github.com) 下载并安装 ultimatevocalremovergui
AssetStudio 解出来的 AudioCllip 目录下有个 op_short.wav 是 Desire, 总共 2:04
使用 UVR5 将该音频分割成 BGM + 人声
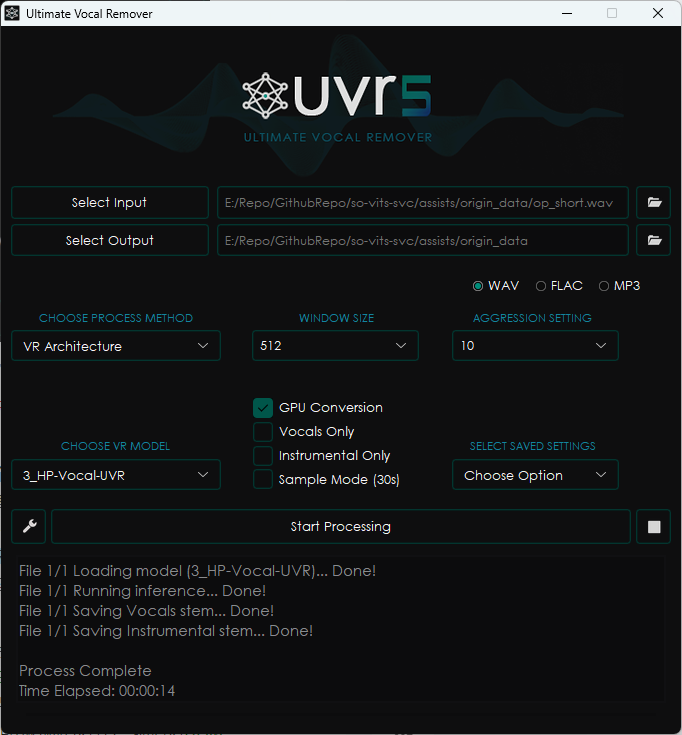
效果还是很不错的
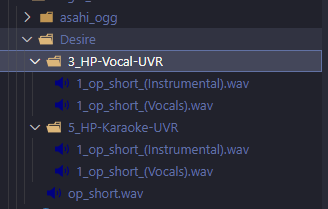
分别用
3_HP-Vocal-UVR和5_HP-Karaoke-UVR分离了试试, 前者分离出的 BGM 不包含和声, 后者包含
开始推理
得到人声干声之后就可以进行推理了, 将干声文件放在 raw 目录下
根据注释修改 inference_main.py 中的如下行
- 更改
model_path为你自己训练的最新模型记录点- 将待转换的音频放在
raw文件夹下clean_names写待转换的音频名称trans填写变调半音数量spk_list填写合成的说话人名称
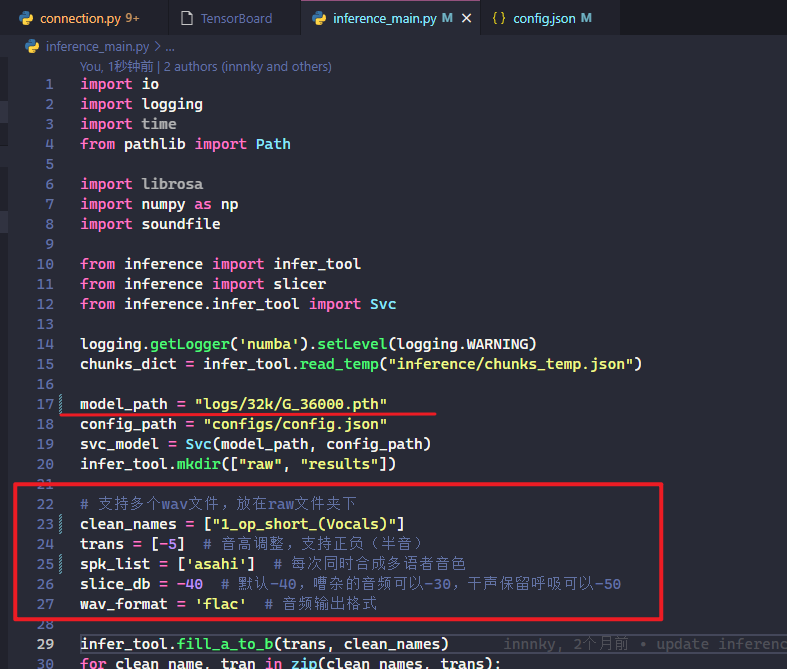
执行 inference_main.py
python .\inference_main.py
然后就可以在 results 目录下看到推理结果了
