SQL(Relational) Databases
SQL(Relational) Databases
- SQL(Relational) Databases
- 创建 SQLAlchemy
- 引入 SQLAlchemy 库
- 为 SQLAlchemy 创建 database URL
- 创建 SQLAlchemy engine
- 创建一个 SessionLocal 类
- 创建一个 Base 类
- 创建 database models
- 从 Base 类创建 SQLAlchemy model
- 创建 model attributes/columns
- 创建 relationships
- 创建 Pydantic model
- 创建 initial Pydantic models / schemas
- 创建用于 reading / returning 的 Pydantic models / schemas
- 使用 Pydantic 的 orm_mode
- CRUD utils
- Main FastAPI app
- 创建数据库表
- 创建 dependency
- Prisma
- 数据库操作(慕课网)
示例项目结构:
sql_app__init__.pycrud.pydatabase.pymain.pymodels.pyschemas.py
__init__.py是个空文件,它只是为了让 Python 识别这是一个 module。
创建 SQLAlchemy
首先要装下 SQLAlchemy 库
pip install sqlalchemy
编辑 database.py 文件
引入 SQLAlchemy 库
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
为 SQLAlchemy 创建 database URL
SQLALCHEMY_DATABASE_URL = "sqlite:///E:/ProgrammingLessons/Vue/vite/ViteLearningBackend/ViteLearningBackend.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
在本次示例中, 使用 SQLite 作为数据库, 在 E:/ProgrammingLessons/Vue/vite/ViteLearningBackend/ 目录下有一个 ViteLearningBackend.db 数据库文件, 因此 URL 最后部分是 E:/ProgrammingLessons/Vue/vite/ViteLearningBackend/ViteLearningBackend.db
如果使用 PostgreSQL 的话可以如注释这般使用
使用其他数据库的话把 sqlite 字段相应的换成 MySQL, mariadb 等即可
创建 SQLAlchemy engine
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
connect_args={"check_same_thread": False} 字段只有在使用 SQLite 时才需要
SQLite 默认只允许一个线程通信, 假设每个线程处理一个独立的请求
这是为了防止意外地为不同请求共享相同的 connection
但是在 FastAPI 的函数中, 不止一个 thread 可以向 database 发起请求, 所以我们需要让 SQLIte 知道它应当通过
connect_args = {"check_same_thread": False}允许这些 thread 向数据库发请求
创建一个 SessionLocal 类
SessionLocal 类的每个实例都是一个 database session, 不过该类本身并非 database session(数据库会话)
但是一旦我们创建了一个 SessionLocal 类的示例, 那么这个实例将会成为实际的 database session
我们将其命名为 SessionLocal 以与从 SQLAlchemy 中引入的 Session 相区分
使用 sessionmaker 来创建一个 SessionLocal 类
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
创建一个 Base 类
使用 declarative_base 来返回一个类赋给 Base
后面我们会继承这个类来创建每个数据库的 model 和 class(ORM models)
Base = declarative_base()
创建 database models
编辑 models.py
从 Base 类创建 SQLAlchemy model
SQLAlchemy 使用术语 "model" 来指代这些与数据库交互的 class 及 instance
不过需要注意的是 Pydantic 也使用术语 "model" 来指代不同的东西, data validation, coversion, documentation classes 以及 instances
从 database.py 引入 Base 类
创建继承于 Base 类的子类
这些子类都是 SQLAlchemy model
from .database import Base
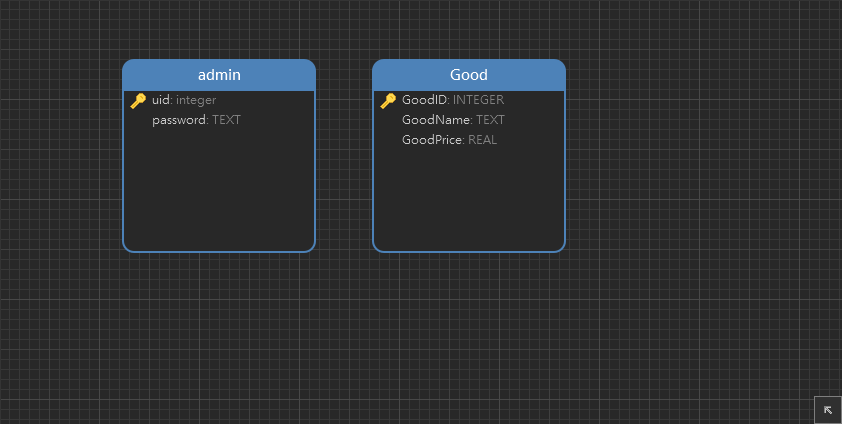
class Admin(Base):
__tablename__ = "admin"
class Good(Base):
__tablename__ = "Good"
# 因为这里是直接在 jupyter笔记本里写的, 已经运行过代码块了直接使用 Base 即可
# from .database import Base
from tokenize import Double
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String, FLOAT
from sqlalchemy.orm import relationship
class Admin(Base):
__tablename__ = "admin"
uid = Column(Integer, primary_key=True, index=True)
password = Column(String)
class Good(Base):
__tablename__ = "Good"
GoodID = Column(Integer, primary_key=True, index=True)
GoodName = Column(String)
GoodPrice = Column(FLOAT)
__tablename__ 属性告诉 SQLAlchemy 在数据库中为每个 model 使用的表名
创建 model attributes/columns
创建所有 model 的 attribute
这些 attribute 对应的表示数据库相应表中的一列
我们使用 SQLAlchemy 中的 Column 作为默认值
然后传递一个 SQLAlchemy 类 "type", 作为 Interger, String, 或者 Boolean, 将数据库中的字段类型定义为一个参数
创建 relationships
个人写的示例中没有定义外键, 因为后面要加速开发原型, 所以个人示例比较简略
因此这部分搬下官方示例
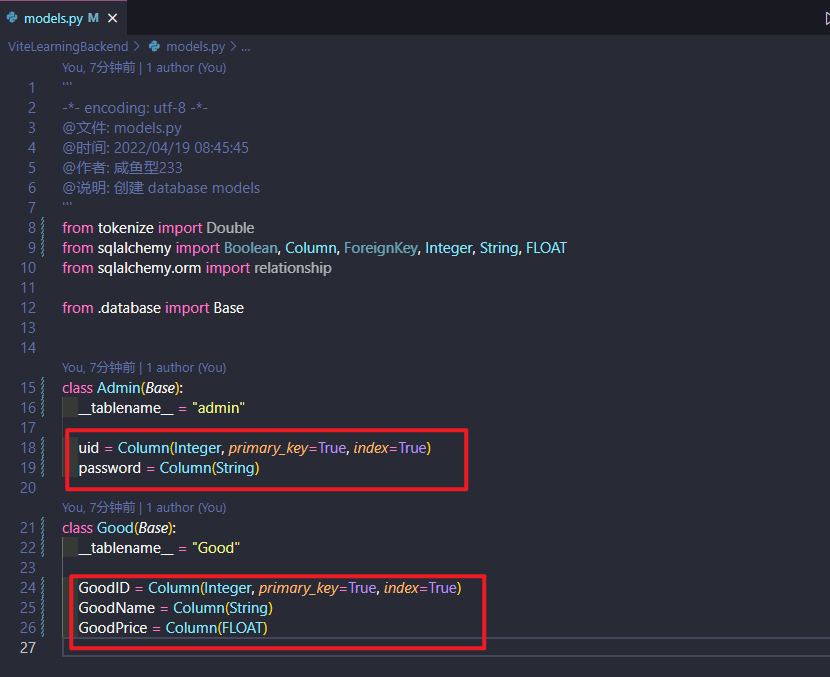
我们使用 SQLAlchemy ORM 提供的 relationship 来创建 relationship
这将或多或少称为一个 "magic" attribute, 他讲包含与此表关联的其他表的值
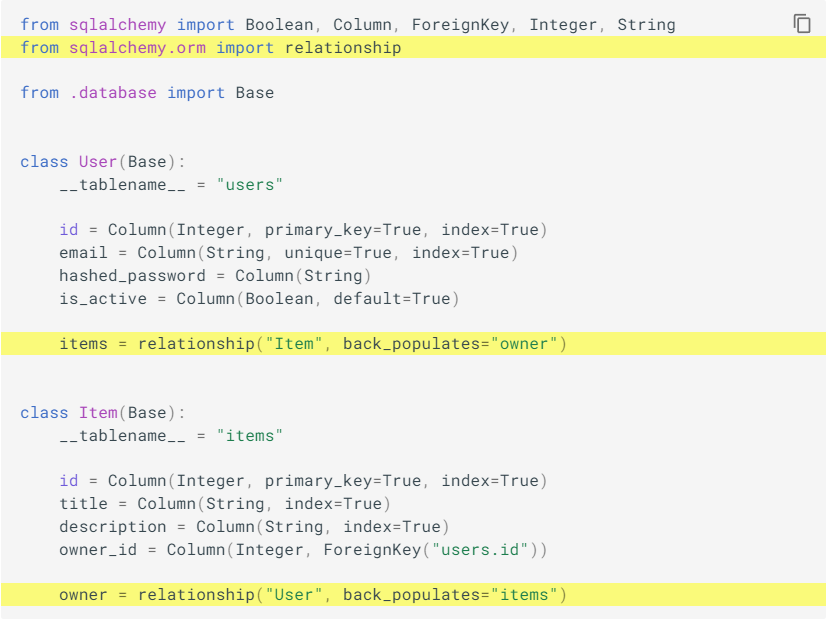
当我们从 User 中访问 items 属性时, 比如 my_user.items, 他将生成一个 Item SQLAlchemy models 列表(来自 items 表), 其中有一个外键指向 users 表中的这个记录
当访问 my_usr.items 时, SQLAlchemy 实际上会从数据库的 items 表中查询到这些 items并填入这里
当我们访问 Item 中的 owner 属性时, 他将包含来自 users 表的 User SQLAlchemy model; 他将使用 onwer_id attribute/column 及其外键来决定从 users 表中获取哪些记录
创建 Pydantic model
编辑 schemas.py
为了避免
SQLAlchemy models和Pydantic models之间的混淆,我们在models.py中创建SQLAlchemy models, 在shcemas.py中创建Pydantic models
这些
Pydantic models或多或少地定义了一个"schema"(一个有效的data shape)。
因此,这将有助于我们避免在使用二者时可能产生的混淆
创建 initial Pydantic models / schemas
创建一个 StaffBase Pydantic model (或者说 schema) 一遍在创建和读取数据时由公共属性
然后创建一个 StaffCreate 继承自 StaffBase
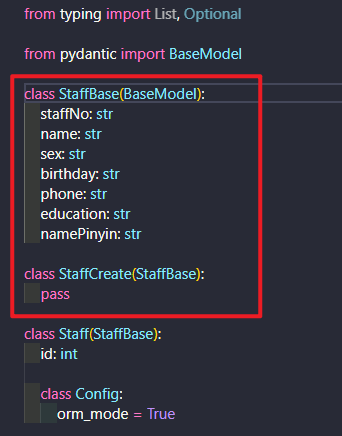
SQLAlchemy style 和 Pydantic style
在 SQLAlchemy models 中定义属性时使用的是 =, 并将类型作为参数传给 Column, 如下:
name = Column(String)
然而在 Pydantic models 中使用 : 声明这些类型, 如下:
name: str
创建用于 reading / returning 的 Pydantic models / schemas
创建 Pydantic models(schemas), 当从 API 返回数据时, 将在读取数据时使用它
例如, 在创建一个 staff 时我们不知道他的 id 是什么, 但是当读取他(从 API 返回他) 时, 我们已经知道它的 ID
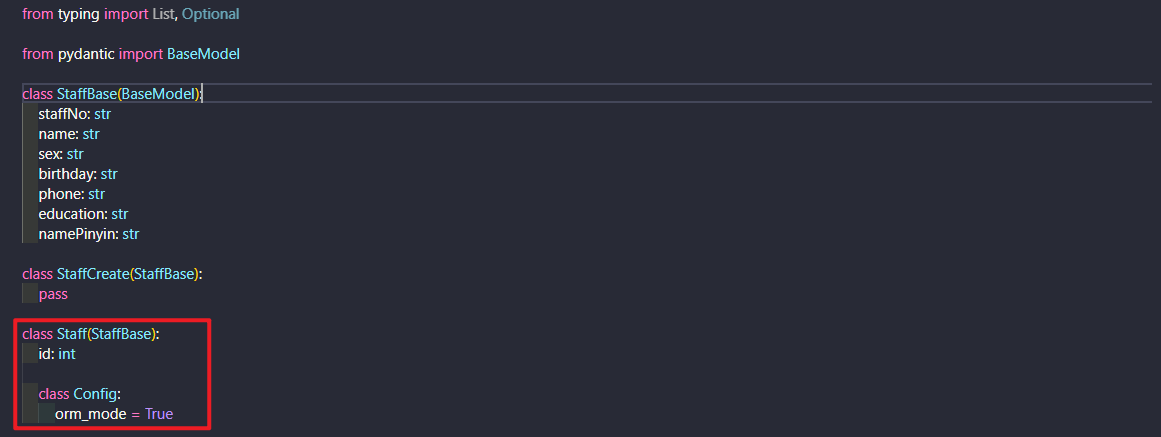
使用 Pydantic 的 orm_mode
现在, 在 Pydantic models 中为了方便读取, 给 Staff 类添加一个内部的 Config 类
这个 Config 类用于向 Pydantic 提供配置
在 Config 类中, 将 orm_mode 属性设置为 True
需要注意的是使用
=进行赋值
它不像前面一样使用:进行类型声明
这是设置一个配置值而非声明一个类型
Pydantic 的 orm-mode 会告诉 Pydantic model 读取数据, 即便它并非是个 dict 而是 ORM model(或者其他任何具有属性的任意对象)
如此一来, 不再只是类似如下操作一样从 dict 中获取类型:
id = data['id']
它也会尝试从属性中获取到 id, 如:
id = data.id
有了这些, Pydantic model 就和 ORM 兼容了, 并且你可以只在 path 操作中的 response_model 参数中声明它
您将能够返回一个 database model, 并从中读取数据
关于 ORM mode 的技术细节
SQLAlchemy 和许多其他的默认方法是“lazy loading”。
这意味着,例如,它们不会从数据库中获取关系数据,除非您尝试访问将包含该数据的属性。
例如,访问 items 属性:
current_user.items
将使 SQLAlchemy 转到 items 表并获取该用户的条目,但不是在此之前。
如果没有 orm_mode,则如果从路径操作返回 SQLAlchemy 模型,它将不包含关系数据。
即使你在你的 Pydantic 模型中声明了这些关系。
但是在 ORM 模式下,由于 Pydantic 本身将尝试从属性访问它需要的数据(而不是假设 dict) ,你可以声明你想要返回的特定数据,它将能够去获取它,甚至是从 ORM。
CRUD utils
编辑 crud.py
在这个文件中,我们将使用可重用的函数与数据库中的数据进行交互。
CRUD 来自: Creat(创建)、Read(读取)、Update(更新) 和 Delete(删除)。
'''
Author: 咸鱼型233
Date: 2022-04-25 16:35:15
LastEditors: 咸鱼型233
LastEditTime: 2022-04-25 20:29:15
FilePath: \VbenBackend\sql_app\curd.py
Description:
Copyright (c) 2022 by 咸鱼型233, All Rights Reserved.
'''
'''
-*- encoding: utf-8 -*-
@文件 :curd.py
@时间 :2022/04/18 21:07:48
@作者 :咸鱼型233
@说明 :
'''
from sqlalchemy.orm import Session
from . import models, schemas
# 通过 id 读取 Staff
def get_staff(db: Session, id: int):
return db.query(models.Staff).filter(models.Staff.id == id).first()
# 通过 staffNo 读取 Staff
def get_staff_by_staffNo(db: Session, staffNo: str):
return db.query(models.Staff).filter(models.Staff.staffNo == staffNo).first()
# 获取所有 Staff
def get_staffs(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.Staff).offset(skip).limit(limit).all()
# 创建 Staff
def create_staff(db: Session, staff: schemas.StaffCreate):
db_staff = models.Staff(**staff.dict())
db.add(db_staff)
db.commit()
db.refresh(db_staff)
return db_staff
# 更新 staffNo
def update_staff_staffNo(db: Session, id: int, staffNo: str):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db_staff.staffNo = staffNo
db.commit()
return db_staff
# 更新 name
def update_staff_name(db: Session, id: int, name: str):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db_staff.name = name
db.commit()
return db_staff
# 更新 sex
def update_staff_sex(db:Session, id: int, sex:str):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db_staff.sex = sex
db.commit
return db_staff
# 更新 birthday
def update_staff_birthday(db:Session, id: int, birthday:str):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db_staff.birthday = birthday
db.commit
return db_staff
# 更新 phone
def update_staff_phone(db:Session, id: int, phone:str):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db_staff.phone = phone
db.commit
return db_staff
# 更新 education
def update_staff_education(db:Session, id: int, education:str):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db_staff.education = education
db.commit
return db_staff
# 更新 namePinyin
def update_staff_namePinyin(db:Session, id: int, namePinyin:str):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db_staff.namePinyin = namePinyin
db.commit
return db_staff
# 删除 Staff
def delete_staff(db: Session, id: int):
db_staff = db.query(models.Staff).filter(models.Staff.id == id).first()
db.delete(db_staff)
db.commit()
return db_staff
Main FastAPI app
编辑 main.py
创建数据库表
用一种非常简单的方式创建数据库表
models.Base.metadata.create_all(bind=engine)
创建 dependency
现在使用我们在 sql_app/databases.py 文件中创建的 SessionLocal 类创建一个依赖项。
我们需要每个请求都有一个独立的数据库会话/连接(SessionLocal) ,在所有请求中使用同一个会话,然后在请求完成后关闭它。
然后为下一个请求创建一个新会话。
为此,我们将创建一个带有 yield 的新 dependency,如前面关于 Dependencies 与 yield 的部分所解释的那样。
我们的依赖项将创建一个新的 SQLAlchemy SessionLocal,它将在单个请求中使用,然后在请求完成后关闭它。
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
我们将
SessionLocal()的创建和请求的处理放在一个 try 块中。
然后我们在 finally 块关闭它。 这样我们就可以确保在请求之后数据库会话总是关闭的。即使在处理请求时出现异常。 但是您不能从退出代码(在 yield 之后)中引发另一个异常
然后,当在路径操作函数中使用依赖项时,我们使用直接从 SQLAlchemy 导入的 Session 类型声明它。
这样我们就可以在路径操作函数中获得更好的编辑器支持,因为编辑器会知道 db 参数的类型是 Session:
Prisma
Prisma Client Python (prisma-client-py.readthedocs.io)
Prisma - Next-generation Node.js and TypeScript ORM for Databases
[TODO: 前端 TS 能用, 后端可以用 Prisma-python, 看起来比 SQLAlchemy 好用, 下个项目准备上 Prisma && Prisma-python]
数据库操作(慕课网)
配置 SQLAlchemy ORM
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
import os
# sqlite 数据库 url
SQLALCHEMY_DATABASE_URL = "sqlite:///E:/GithubProject/Vben/VbenBackend/static/data/vben.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
# 创建 SQLAlchemy 引擎
engine = create_engine(
SQLALCHEMY_DATABASE_URL,
encoding='utf-8',
# echo=True表示引擎将用repr()函数记录所有语句及其参数列表到日志
echo=True,
# 由于SQLAlchemy是多线程,
# 指定check_same_thread=False来让建立的对象任意线程都可使用。
# 这个参数只在用SQLite数据库时设置
connect_args={"check_same_thread": False}
)
# 在SQLAlchemy中,CRUD都是通过会话(session)进行的,
# 所以我们必须要先创建会话,每一个SessionLocal实例就是一个数据库session
# 创建SessionLocal 类
SessionLocal = sessionmaker(
# commit()是指提交事务,将变更保存到数据库文件
autocommit=False,
# flush()是指发送数据库语句到数据库,但数据库不一定执行写入磁盘;
autoflush=False,
bind=engine
)
# 创建一个 Base 类, 后面继承这个类来创建每个数据库的 ORM Model
Base = declarative_base()
DataBase Models
'''
Author: 咸鱼型233
Date: 2022-04-28 16:38:14
LastEditors: 咸鱼型233
LastEditTime: 2022-04-30 23:54:14
FilePath: \VbenBackend\app\model.py
Description: database model
Copyright (c) 2022 by 咸鱼型233, All Rights Reserved.
'''
from xml.etree.ElementTree import Comment
from sqlalchemy import (
Boolean,
Column,
ForeignKey,
Integer,
String,
FLOAT,
BigInteger,
Date,
DateTime,
func,
)
from sqlalchemy.orm import relationship
from .database import Base
# 部门/科室类
class Department(Base):
"""部门类
"""
__tablename__ = "department" # 表名
did = Column(Integer, primary_key=True, nullable=False, comment = "部门id")
dname = Column(String(30), nullable=False, comment="部门名称")
# 关联 <- staff.did
staffs = relationship("Staff", back_populates="reDid")
# 当数据创建或者更新时插入当前时间
created_at = Column(DateTime, server_default=func.now(), comment="创建时间")
updated_at = Column(DateTime, server_default=func.now(),
onupdate=func.now(), comment="更新时间")
# # 排序相关(新版 SQLAlchemy 已弃用)
# __mapper_args__ = {
# # 倒序的话可以使用 "order_by": did.desc()
# "order_by": did
# }
# 显示类对象
def __repr__(self):
return f"<Department {self.did}_{self.dname}>"
# 员工类
class Staff(Base):
"""员工类
"""
__tablename__ = "staff" # 表名
sid = Column(Integer, primary_key=True, nullable=False, comment="员工id")
sname = Column(String(30), nullable=False, comment="员工姓名")
did = Column(Integer, ForeignKey("department.did"), comment="员工所属单位id") # 外键
# 外键 -> department.did
reDid = relationship("Department", back_populates="staffs")
# 当数据创建或者更新时插入当前时间
created_at = Column(DateTime, server_default=func.now(), comment="创建时间")
updated_at = Column(DateTime, server_default=func.now(),
onupdate=func.now(), comment="更新时间")
# # 排序相关(新版 SQLAlchemy 已弃用)
# __mapper_args__ = {
# # 倒序的话可以使用 "order_by": did.desc()
# "order_by": sid
# }
# 显示类对象
def __repr__(self):
return f"<Staff {self.sid}_{self.sname}_{self.did}>"
# 用户类
class User(Base):
"""用户类
"""
__tablename__ = "user"
uid = Column(Integer, primary_key=True, nullable=False, autoincrement=True, comment="用户id")
account = Column(Integer, nullable=False, comment="账号")
password = Column(String(30), nullable=False, comment="密码")
uname = Column(String(30), comment="用户名")
role = Column(Integer, nullable=False, comment="身份组")
mapper_args = {"order_by":...-慕课网 (imooc.com)
新版本的 sqlalchemy 丢弃了 mappter_args 当中设置的方法
应当用 db.query().order_by() 直接在 Query 对象后面显示地调用 order_by 函数
例如:
db.query(models.City).order_by(models.City.province).offset().limit().all() db.query(models.Data).order_by(models.Data.confirmed)....