sovits 4.0 使用随笔
大约 3 分钟
sovits 4.0 使用随笔
吸取了之前 3.2 的复现经验后这次直接参考仓库中给出的 Colab 一键脚本进行操作
环境搭建
torch 与 CUDA 版本
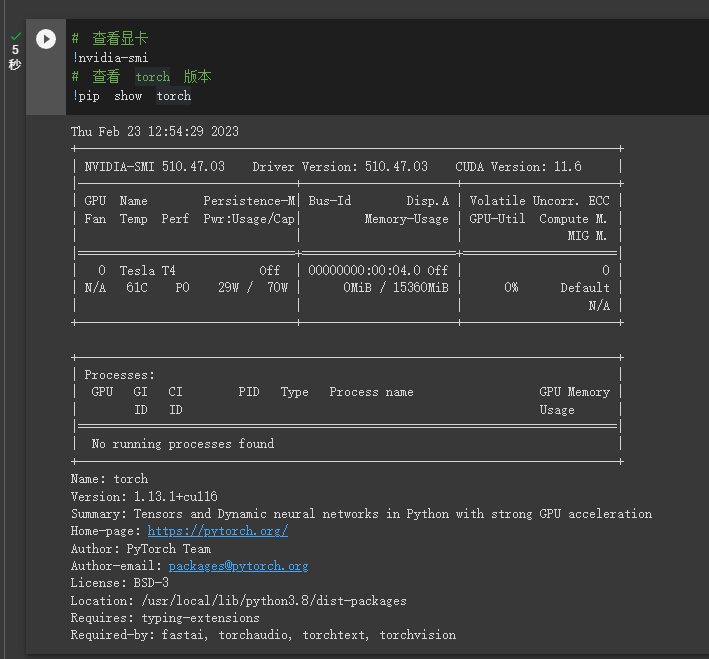
torch 1.13.1 + CUDA 11.6, 因此直接沿用之前在 32k 分支中所创建的 conda 环境了
克隆仓库, 安装依赖
# clone 4.0 分支
git clone https://github.com/innnky/so-vits-svc -b 4.0
cd /content/so-vits-svc
# 安装依赖
pip install pyworld praat-parselmouth fairseq
慢的话可以换源
-i https://mirrors.cloud.tencent.com/pypi/simple/conda 环境在开着系统代理时似乎会报错
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1131)'))'目前没有找到开着代理还能解决该问题的方案, 因此选择了关闭代理并换源
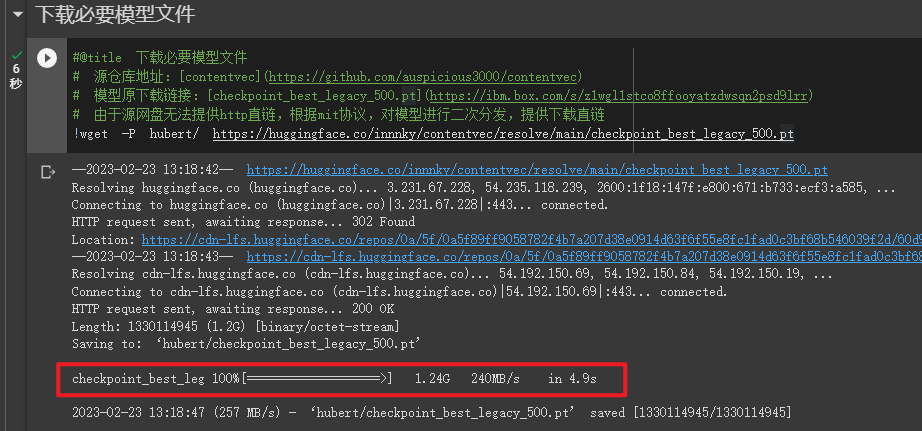
下载模型文件
# 下载必要模型文件
# 源仓库地址:[contentvec](https://github.com/auspicious3000/contentvec)
# 模型原下载链接:[checkpoint_best_legacy_500.pt](https://ibm.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr)
# 由于源网盘无法提供http直链,根据mit协议,对模型进行二次分发,提供下载直链
# (linux)
wget -P hubert/ https://huggingface.co/innnky/contentvec/resolve/main/checkpoint_best_legacy_500.pt
# (Windows)
Invoke-WebRequest -Uri "https://huggingface.co/innnky/contentvec/resolve/main/checkpoint_best_legacy_500.pt" -OutFile ".\hubert\checkpoint_best_legacy_500.pt"
PS: 该文件有 1.24 G, Windows 下方便的话还是直接用工具下载下来再放到对应目录下比较快
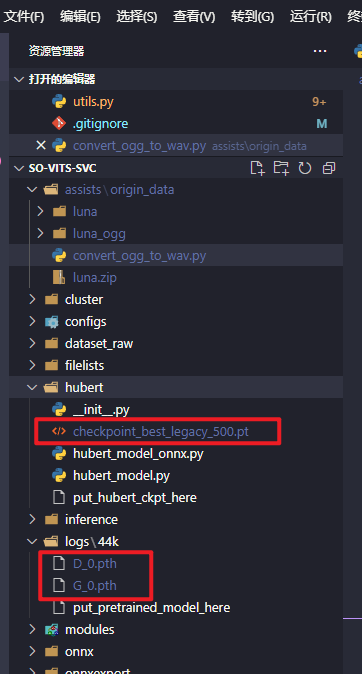
直接打开链接下载完放在
logs/44k目录下即可, 用Invoke-WebRequest太慢了
数据集准备
以以下文件结构将数据集放入dataset_raw目录即可
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
数据预处理
重采样至 44100hz
python resample.py自动划分训练集 验证集 测试集 以及自动生成配置文件
python preprocess_flist_config.py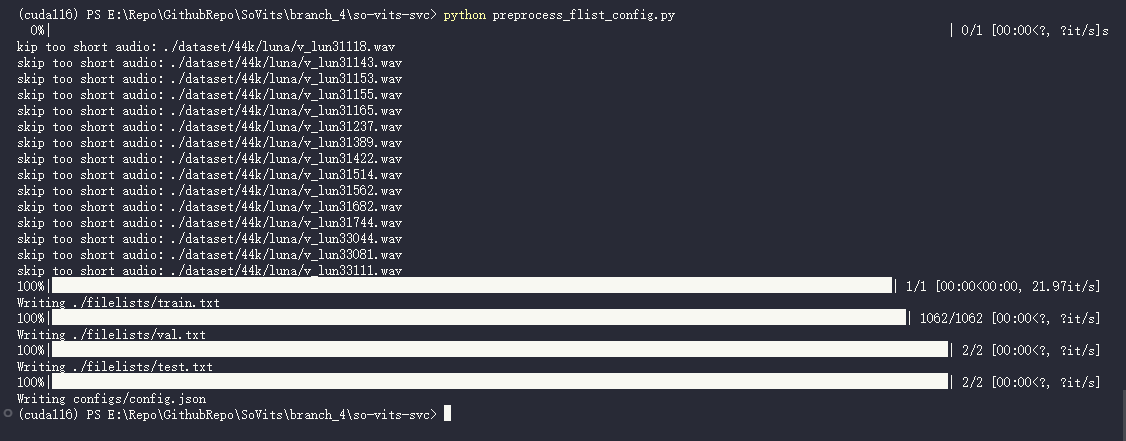
生成hubert与f0
python preprocess_hubert_f0.py
执行完以上步骤后 dataset 目录便是预处理完成的数据,可以删除dataset_raw文件夹了
训练
python train.py -c configs/config.json -m 44k
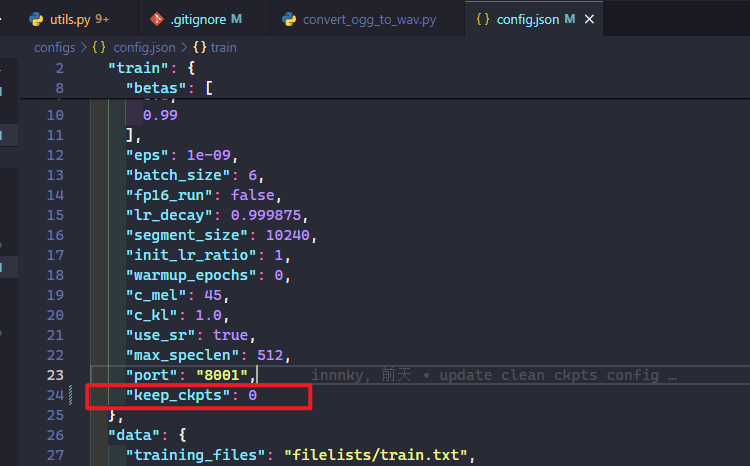
注:训练时会自动清除老的模型,只保留最新3个模型,如果想防止过拟合需要自己手动备份模型记录点,或修改配置文件keep_ckpts 0为永不清除
这里
keep_ckpts默认值为 3, 对应保留 3 个模型然后就可以继续看显卡呼啸了(bushi
数据集从 7000 降到 1000 后训练快了很多

推理
得到人声干声之后就可以进行推理了, 将干声文件放在 raw 目录下
python .\inference_main.py -m "logs/44k/G_44800.pth" -c "configs/config.json" -n "1_op_short_(Vocals).wav" -t 0 -s "luna"
3.0 是直接改该脚本中的参数, 4.0 这里添加了命令行支持
必填项部分
- -m, --model_path:模型路径。
- -c, --config_path:配置文件路径。
- -n, --clean_names:wav 文件名列表,放在 raw 文件夹下。
- -t, --trans:音高调整,支持正负(半音) 。
- -s, --spk_list:合成目标说话人名称。
可选项部分:见下一节
- -a, --auto_predict_f0:语音转换自动预测音高,转换歌声时不要打开这个会严重跑调。
- -cm, --cluster_model_path:聚类模型路径,如果没有训练聚类则随便填。
- -cr, --cluster_infer_ratio:聚类方案占比,范围 0-1,若没有训练聚类模型则填 0 即可。